
LTX 1の動画生成ComfyUIワークフローは、15ノード程度でシンプルに組める。本記事ではノード構成を画面キャプチャ中心で解説する。
シリーズの最終目標は8秒・4K(3840×2160)・60fps・H264 mp4のAdobe Stock投稿用ファイルを作ること。本記事は「生成+60fps補間 → 1024×576・60fps・約8秒の中間mp4」までを扱う。4K化は記事3で解説する。
LTX Videoモデルそのものの概要・ライセンス・入門的な使い方の基礎は、姉妹サイト「AIツール図鑑」のLTX Video入門記事でまとめている。本体実装は Lightricks/LTX-Video 公式 GitHub、モデル重みは Lightricks/LTX-Video Hugging Face で配布されている。
- LTX 1 + RIFE VFI + H264出力のComfyUIノード構成の全体像(スクリーンショット)
- 各ノードの役割と設定値の目安
- モデルファイルの置き場所と入手先のガイドライン
- 手動で組む際につまずきやすいポイント
- 前記事で実測した生成時間・VRAM消費と同じ構成での組み方
- 前提となる記事
- LTX Video モデルの技術仕様
- 必要なモデルファイル一覧
- 必要なカスタムノード
- ワークフロー全体像(スクリーンショット)
- 主要ノードの役割と設定値
- 1. CLIPを読み込む(CLIPLoader)
- 2. チェックポイントを読み込む(CheckpointLoaderSimple)
- 3. CLIPテキストエンコード(CLIPTextEncode)× 2本
- 4. 空のLTXV潜在ビデオ(EmptyLTXVLatentVideo)
- 5. モデルサンプリングLTXV(ModelSamplingLTXV)
- 6. LTXVスケジューラー(LTXVScheduler)
- 7. Kサンプラー選択(KSamplerSelect)
- 8. カスタムサンプラー(SamplerCustom)
- 9. VAEデコード(VAEDecode)
- 10. RIFE VFI(フレーム補間)
- 11. Video Combine(VHS_VideoCombine)
- ComfyUI起動コマンド例
- つまずきやすいポイント
- ノード配置のコツ(視覚設計)
- まとめ:ノードを理解すれば応用も効く
- 参考資料
前提となる記事
本記事はComfyUI上で LTX 1 を実際に動かすためのノード構成解説で、実測値・採用率・GPU選定は前記事で扱っている。
- 前記事: LTX 1は16GB VRAMで商用量産できる|RTX 5080/5060Ti実測+Adobe Stock採用率45%【2026年4月版】
前記事と同じワークフロー構成を本記事で視覚的に解説する形。生成時間の目安(RTX 5080で約5分/本)は前記事を参照されたい。
LTX Video モデルの技術仕様
LTX Video は Lightricks 社が開発した DiT (Diffusion Transformer) ベースの動画生成モデルで、軽量級カテゴリに属する。テキストエンコーダに T5-XXL を採用しており、これは “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer” (Raffel et al., 2019) で提案された Google の汎用テキスト変換モデルである。
LTX Video は DiT (Diffusion Transformer) アーキテクチャを採用した動画生成モデルで、768×512 解像度・24fps の動画を実時間に近い速度で生成する設計が公開されている。
Lightricks/LTX-Video 公式リポジトリ の記述に基づく
| 項目 | LTX Video 2B v0.9.1 | 備考 |
|---|---|---|
| アーキテクチャ | DiT (Diffusion Transformer) | 2024年公開 |
| パラメータ数 | 約2B | 軽量級カテゴリ |
| テキストエンコーダ | T5-XXL | Google T5 系列 |
| 標準フレームレート | 24-30fps | RIFE 補間で 60fps 化可能 |
| 推奨解像度 | 768×512 / 1024×576 | 16GB VRAM 想定 |
| ファイルサイズ | 約5.72GB | fp16 重み |
| ライセンス | 公式リポジトリ参照 | 商用利用前に要確認 |
必要なモデルファイル一覧
ComfyUIのmodelsディレクトリに以下を配置する。
| ファイル | 配置先 | サイズ | 入手先 |
|---|---|---|---|
| ltx-video-2b-v0.9.1.safetensors | models/checkpoints/ | 5.72 GB | Lightricks公式Hugging Face |
| t5xxl_fp16.safetensors | models/clip/ | 約9.8 GB | ComfyUI公式またはStabilityAI Hugging Face |
| rife49.pth | comfyui-frame-interpolation/ckpts/rife/ | 数十MB | ComfyUI-Frame-Interpolation カスタムノード同梱 |
合計約16GBのダウンロードが必要。NVMe SSDの空き容量を確認しておくこと。RIFE (Real-Time Intermediate Flow Estimation) の技術背景は “RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation” (Huang et al., 2020) で解説されており、本記事で使用する rife49 はその実装系統の重みファイルである。
必要なカスタムノード
ComfyUI Manager(または手動インストール)で以下を導入する。
- ComfyUI-LTXVideo: LTX動画生成本体(LTXVConditioning, LTXVScheduler等)
- ComfyUI-Frame-Interpolation: RIFE VFI によるフレーム補間 — リポジトリは Fannovel16/ComfyUI-Frame-Interpolation
- ComfyUI-VideoHelperSuite: 動画mp4書き出し用(VHS_VideoCombine)
ComfyUI本体(comfyanonymous/ComfyUI)に加えて上記3つのカスタムノードセットが揃えば、LTX 1のフル生成ワークフローが組める。
ワークフロー全体像(スクリーンショット)
下記は本ワークフローで使用しているLTX 1 + RIFE VFI の基本構成。ComfyUIノードの接続関係を示している。
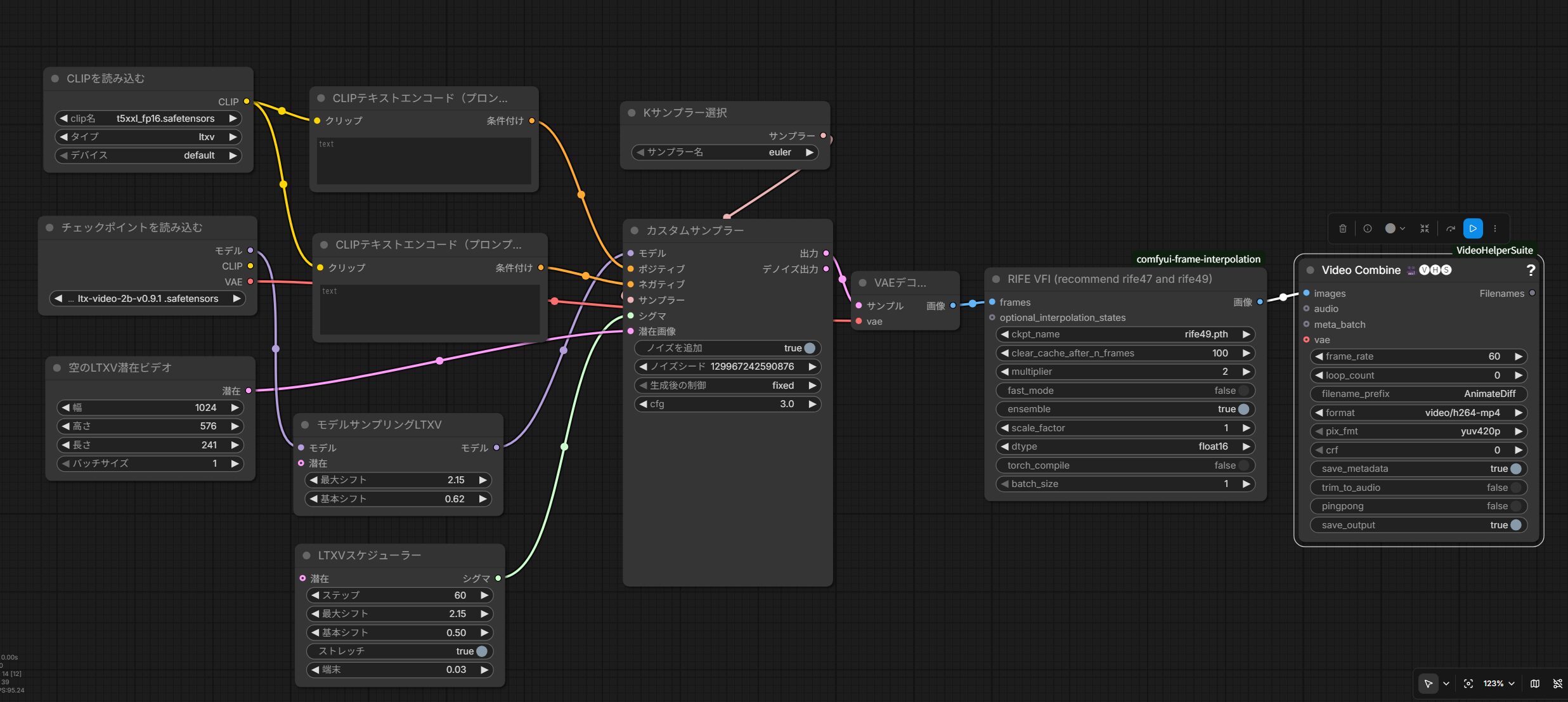
左から右へ流れる基本形。CLIPとCheckpointをロード→プロンプトをエンコード→空のLatent Videoを作成→スケジューラとサンプラーで生成→VAEデコード→RIFE VFIで補間→H264 mp4書き出し、というComfyUIの定石通りの並びである。
主要ノードの役割と設定値
1. CLIPを読み込む(CLIPLoader)
役割: プロンプトの日本語・英語テキストをAIが扱える数値ベクトルに変換する「翻訳機」のロード。LTX 1はT5-XXLというモデルをテキスト変換に使っている。
以下を設定。
- clip_name:
t5xxl_fp16.safetensors - type:
ltxv - device:
default
2. チェックポイントを読み込む(CheckpointLoaderSimple)
役割: 動画生成の「本体」であるモデルファイルを読み込む。ここで指定したモデルが動画の絵柄やモーションを決める。
- ckpt_name:
ltx-video-2b-v0.9.1.safetensors
このノードからは Model / CLIP / VAE の3出力が出るが、CLIPはCLIPLoader側の出力を優先するため、本ワークフローではModel と VAE のみ使う。
3. CLIPテキストエンコード(CLIPTextEncode)× 2本
役割: 実際のプロンプト文字列をCLIPLoaderで用意した「翻訳機」に通して、モデルが理解できる数値に変換する。「こういう映像にしてほしい」というPositive と「こういうのは避けて」というNegative の2本用意するのが基本。
LTX 1向けのプロンプト例は前記事を参照。
4. 空のLTXV潜在ビデオ(EmptyLTXVLatentVideo)
役割: 生成する動画の「空のキャンバス」を用意するノード。ここで解像度・フレーム数・バッチサイズを決める。後段のサンプラーがこのキャンバスにノイズを埋めていき、徐々に動画が浮かび上がる仕組み。
- width: 1024(例)
- height: 576(例)
- length: 241(フレーム数)
- batch_size: 1
5. モデルサンプリングLTXV(ModelSamplingLTXV)
役割: LTXV専用の「動きの激しさ」の調整ノブ。max_shift と base_shift を上げるとダイナミックな動きが強調され、下げると落ち着いた表現になる。
- max_shift: 2.15(例)
- base_shift: 0.62(例)
6. LTXVスケジューラー(LTXVScheduler)
役割: ノイズを何ステップで動画に変えていくかの「段取り表」を作る。ステップ数が多いほど時間はかかるが、細部が丁寧になる。50前後が品質と時間のバランス良い定番値。
- steps: 50(例)
- max_shift / base_shift: 上と同値
- stretch: true
- terminal: 0.03
7. Kサンプラー選択(KSamplerSelect)
役割: ノイズを除去していく具体的な「計算手順」を選ぶノード。同じプロンプトでも選ぶアルゴリズムで仕上がりのテイストが変わる。LTX 1では euler(シンプル・安定)または dpmpp_2m(やや品質高め)が無難。
サンプラーごとの特性を整理しておく。
| Sampler | 速度 | 仕上がり傾向 | LTX 1での推奨度 |
|---|---|---|---|
| euler | 最速 | シンプル・安定 | デフォルト推奨 |
| dpmpp_2m | やや遅い | 細部が丁寧 | 品質詰め時 |
| dpmpp_3m_sde | 遅い | ノイズ収束高品質 | 静止画寄り、動画は過剰 |
| uni_pc | 速い | 少ステップで収束 | ステップ数 30 未満で検討 |
当サイト検証では euler を基本にし、品質を詰めたい場面のみ dpmpp_2m に切り替える運用が安定している。RTX 5080 で steps=50 / euler の場合の1本あたり生成時間は前記事で実測値を示している。
8. カスタムサンプラー(SamplerCustom)
役割: ここまで用意してきた全要素(モデル・プロンプト・スケジューラ・サンプラー・キャンバス)を受け取り、実際に動画生成処理を走らせる「生成本体」ノード。CFG値はプロンプトへの忠実度で、高すぎると破綻、低すぎると指示を無視される。3.0前後が無難。
- cfg: 3.0(例)
- noise_seed: 任意の整数
- add_noise: true
9. VAEデコード(VAEDecode)
役割: サンプラーが出力する「内部表現(潜在空間)」を、人間が見られるピクセル画像(フレーム)に変換する翻訳ノード。
通常版(VAEDecode) と タイル分割版(VAEDecodeTiled) の違い
| ノード | VRAM 消費 | 速度 | 継ぎ目・ズレ | 推奨ケース |
|---|---|---|---|---|
| VAEDecode(通常版・no tile) | 多い | 遅い | なし | ストック素材・最終提出 |
| VAEDecodeTiled | 少ない | 速い | 稀に発生 | VRAM 不足時・検証時 |
本記事のストック素材運用では継ぎ目・ズレを嫌うため、多少時間がかかっても通常版(no tile)のVAEDecodeを使用している。VRAMが足りない場合や速度優先の検証時はVAEDecodeTiledで妥協する形。
10. RIFE VFI(フレーム補間)
役割: LTX 1が出した30fpsの動画を、AIで中間フレームを自動生成して60fpsに倍化するノード。ヌルッとした滑らかな動きになり、ストック素材としての見栄えが大きく上がる。multiplier=2 で「2倍に補間」という意味。
- ckpt_name:
rife49.pth - multiplier: 2(倍率、x2で60fps化)
- fast_mode: false(品質優先)
- ensemble: true(品質優先)
- clear_cache_after_n_frames: 100
11. Video Combine(VHS_VideoCombine)
役割: ここまでで生成されたフレーム群を、最終的にmp4動画ファイルにまとめて書き出す出力ノード。内部的にFFmpegを呼び出している(FFmpeg 公式ドキュメント)。
crf=0 にしておく理由: 本ワークフローの出力はまだ最終ファイルではなく、次段の4Kアップスケール工程に入力する中間ファイル。crf=0(可逆圧縮)で書き出しておくことで、アップスケール時の画質劣化の起点をゼロにできる。Adobe Stockへの最終提出ファイル化(4Kアップスケール)の手順は続編記事で扱う。
- frame_rate: 60
- format:
video/h264-mp4 - pix_fmt:
yuv420p - crf: 0(可逆圧縮)
ComfyUI起動コマンド例
LTX 1 + RIFE VFI のワークフローを回すにあたり、ComfyUI は以下のようなオプション付きで起動すると安定する。Windowsの場合は .bat ファイルに書いておいて起動のたびにダブルクリックするのが楽。
@echo off
setlocal
cd /d "%~dp0"
echo ===================================================
echo [ ComfyUI for LTX 1 / VAE No-Tile ]
echo ===================================================
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.8,max_split_size_mb:128
.\python_embeded\python.exe -s ComfyUI\main.py ^
--windows-standalone-build ^
--normalvram ^
--reserve-vram 1.5 ^
--bf16-unet ^
--bf16-text-enc ^
--preview-method none
pauseオプションの意味
PYTORCH_CUDA_ALLOC_CONF: VRAM断片化を抑制する設定。長時間稼働で断片化によるOOMが減る--normalvram: 16GB VRAM想定のメモリ管理モード(未指定だと別モードになりOOMしやすい)--reserve-vram 1.5: 他のアプリ用にVRAMを1.5GB残しておく設定--bf16-unet/--bf16-text-enc: モデル本体とテキストエンコーダをbf16精度で動かす(VRAM節約+ほぼ無損失)--preview-method none: ComfyUI画面の生成中プレビューを無効化(プレビュー用のVRAMを節約)
出力先ディレクトリ・ポート番号・使用GPUなどの環境依存オプションは各自の環境に合わせて追加する。複数GPU構成の場合は --cuda-device N や --port XXXX を各batで分ければ、ComfyUIを複数同時起動できる。当サイト検証環境では RTX 5080 と RTX 5060 Ti を --cuda-device 0 / --cuda-device 1 で振り分けて並列稼働させている。
つまずきやすいポイント
1. CLIP typeを「ltxv」に設定し忘れる
CLIPLoaderの type が別のモードになっているとエンコードが意味をなさず、生成結果が崩れる。必ず ltxv を選ぶこと。
2. RIFE VFI の ckpt ファイルがない
ComfyUI-Frame-Interpolation をインストールしただけでは rife49.pth が自動取得されないケースがある。手動で custom_nodes/comfyui-frame-interpolation/ckpts/rife/rife49.pth に配置する必要がある。
3. VRAM 16GBで --normalvram 未指定
ComfyUI起動時に --normalvram オプションを付けないと、一部のメモリ管理がデフォルトになりOOMが起きやすい。16GB環境は --normalvram を明示推奨。
4. H264エンコード時にFFmpegが無い
VHS_VideoCombineはFFmpegを使う。PATHが通っていないと書き出し失敗する。Windowsでは winget install ffmpeg または公式バイナリ導入。FFmpeg の H.264 エンコーダ設定の詳細は FFmpeg Wiki: H.264 Encoding Guide を参照。
5. T5-XXL fp16 が重すぎる場合
メモリ圧迫時は fp8 版(t5xxl_fp8_e4m3fn)に切り替えると VRAM を数GB節約できる。生成品質への影響は軽微。
6. PyTorch / CUDA バージョン不整合
RTX 50 系で動かす場合、新世代アーキ向け CUDA 対応の PyTorch ビルドが必要。古い CUDA ランタイムのままだと新世代 GPU の CUDA カーネルが起動できず、CPU フォールバックで極端に遅くなるか起動自体失敗する。NVIDIA の対応情報は CUDA Toolkit Release Notes で確認できる。
ノード配置のコツ(視覚設計)
ComfyUIのキャンバスは自由配置だが、実用上は「データフローが左→右で流れる」ように配置すると、後で見返した時に混乱しにくい。
- 左端: CLIPとCheckpointの読み込み系
- 中央左: プロンプトエンコードとLatent空間設定
- 中央: スケジューラ・サンプラー(生成の核)
- 中央右: VAEデコード
- 右端: RIFE VFI → Video Combine
配線はできるだけ交差させず、似た目的のノードは近接配置すると、デバッグや設定変更時のストレスが減る。
まとめ:ノードを理解すれば応用も効く
LTX 1のComfyUIワークフローは15ノード程度のシンプル構成。スクリーンショットを見ながら手動で組めば、1時間前後で動く状態まで到達できる。
JSONコピペで済ませず自分で組むメリットは、後から解像度・フレーム数・サンプラー・CFG値を変えたくなった時に、どのノードを触れば良いかが感覚として身につくこと。商用量産に進むなら、このノード単位の理解が結局は時間を節約してくれる。
続編の「LTX 1動画を4Kアップスケールする|4x-UltraSharpでAdobe Stock向け最終出力する手順」で、このワークフローで生成した動画を4Kアップスケール処理に流す具体手順を解説している。Adobe Stock向け最終提出ファイル(4K 60fps mp4)までの全体像を合わせて確認してほしい。
続編: LTX 1動画を4Kアップスケールする|1段階シンプル法・2段階品質法・バッチ処理法 — このワークフローで生成した動画を4Kアップスケールして Adobe Stock 向け最終出力まで仕上げる手順を解説。
生成層への組み込み
- LTX 1 を AI 自動化の生成層に組み込む全体像 → 量産型AI自動化の4層構造 ─ ストックフォト動画系で動かしている中身
- 量産型として組むか、本数少なく回すかの判断 → 2026年版|AI自動化は本当に稼げるのか?
本記事は AIハードウェア図鑑 編集部 が記載時点の情報をもとに執筆。製品アップデートや第三者ベンチマーク・価格・対応ランタイム等の変動で評価が変わる可能性がある。一定期間経過した内容は再検証を推奨する。
参考資料
- Lightricks 公式 GitHub: LTX-Video リポジトリ
- Hugging Face 公式: Lightricks/LTX-Video モデルカード
- ComfyUI 公式 GitHub: comfyanonymous/ComfyUI
- ComfyUI-Frame-Interpolation 公式 GitHub: RIFE VFI 実装
- arXiv 公式: RIFE – Real-Time Intermediate Flow Estimation for Video Frame Interpolation (Huang et al., 2020)

