
4Kアップスケールとは、低解像度で生成した動画をAIモデルで高解像度化する処理で、Adobe Stock向けストック動画の最終出力に必須の工程である。本記事では「8秒・4K(3840×2160)・60fps mp4」をAdobe Stock投稿用の最終目標として設定し、そこに到達するための1段階法・2段階法・フォルダバッチ処理の3種類を紹介する。
- 最終目標: 8秒・4K(3840×2160)・60fps・H264 mp4(Adobe Stock投稿向け)
- LTX 1で生成した1024×576動画を4K(3840×2160)にアップスケールする3つの方法
- プリリサイズ→4倍アップでメモリを抑えつつ4Kジャストに仕上げる設計
- シンプルな1段階法(初心者向け)・2段階品質法・フォルダバッチ処理法
- 処理時のピークRAM 60GB超(実測)、32GB環境では軽量化が必要な理由
- Adobe Stock向け最終出力(H264 mp4)の設定
- シリーズ記事の位置づけ
- なぜアップスケールが必要か
- 4Kジャストサイズは 3840×2160
- 検証環境
- 必要なモデルファイル
- 【方法A】1段階シンプル法(プリリサイズ→4倍アップ・筆者が過去に使用)
- 方法Aの実測ベンチマーク結果(RTX 5080)
- 【方法B】2段階法(潜在空間アップスケール経由・筆者は非採用)
- 【方法C】フォルダバッチ処理法(4K後ダウンスケール・量産運用向け)
- 入力動画のダウンスケールをどのタイミングでやるか
- ComfyUI起動コマンド例(アップスケール用)
- 最終出力の設定(VHS_VideoCombine)
- 方法A/B/Cの使い分けまとめ
- つまずきやすいポイント
- まとめ:LTX 1 → 4K出力の全体像
- 出典・参考
シリーズ記事の位置づけ
本記事はLTX 1動画生成シリーズの3記事目。前2記事と合わせて読むと、生成から最終出力までの全体フローが把握できる。
- 記事1: LTX 1は16GB VRAMで商用量産できる|RTX 5080/5060Ti実測+Adobe Stock採用率45%
- 記事2: LTX 1をComfyUIで動かすノード構成の全体像
- 本記事(記事3): 4Kアップスケール処理でAdobe Stock向け最終出力
LTX Videoモデル自体の概要・ライセンス・入門的な使い方の基礎は、姉妹サイト「AIツール図鑑」のLTX Video入門記事を参照。本記事はその応用編(4Kアップスケール)に相当する。
なぜアップスケールが必要か
LTX 1の直接生成解像度は1024×576前後で、そのままではAdobe Stockの推奨動画サイズ(1920×1080以上、理想は3840×2160(4K))に届かない。アップスケールで4K相当まで持ち上げることで、審査採用率と売上単価の両方を底上げできる。
動画モデルではなく画像系のアップスケーラーで各フレームを順次処理すれば十分。LTX 1の出力は「絵が出来上がっている状態」なので、超解像化だけでストック素材として流通するレベルに仕上がる。
本記事のゴールは8秒・4K(3840×2160)・60fps・H264 mp4の最終ファイルを作ること。LTX 1は 241フレーム(30fps換算で約8秒)を生成し、記事2で紹介した RIFE VFI x2 により60fpsに補間される。ここまでで「8秒・1024×576・60fps mp4」が手に入るので、あとは本記事で解像度を4K(3840×2160)に引き上げれば Adobe Stock 投稿用の完成ファイルになる。
4Kジャストサイズは 3840×2160
Adobe Stockが推奨する4Kジャストサイズは 3840×2160(16:9)。これを効率よく作るため、筆者は入力を一度 960×540 にプリリサイズしてから4倍アップスケールする設計を使っている。
- 960 × 4 = 3840
- 540 × 4 = 2160
事前のリサイズ値を960×540にすることで、4倍アップスケール後にちょうど4Kジャストに到達する。1024×576を直接4倍すると4096×2304(4K超え)になってしまい、その後さらにリサイズする二重処理が発生するため、プリリサイズで事前にジャストサイズに揃えるほうが処理効率が高い。
検証環境
| GPU | NVIDIA RTX 5080(VRAM 16GB GDDR7) |
|---|---|
| CPU | Intel Core i7-14700F |
| システムRAM | DDR5 96GB |
| ComfyUI | v0.9.1 |
| 入力動画 | 1024×576 / 60fps / 約8秒(LTX 1生成後にRIFE VFI x2で60fpsに補間された中間mp4、crf=0) |
| 出力動画 | 3840×2160 / 60fps / 約8秒 mp4(Adobe Stock向け最終ファイル) |
必要なモデルファイル
| ファイル | 配置先 | サイズ | 入手先 |
|---|---|---|---|
| 4x-UltraSharp.pth | models/upscale_models/ | 約64 MB | Hugging Face / OpenModelDB で “UltraSharp” 検索 |
| RealESRGAN_x4plus.pth(任意) | models/upscale_models/ | 約64 MB | ReaESRGAN公式リポジトリ / Hugging Face |
【方法A】1段階シンプル法(プリリサイズ→4倍アップ・筆者が過去に使用)
筆者が過去に使用していた構成。入力を960×540にプリリサイズしてから4x-UltraSharpで4倍し、3840×2160(4Kジャスト)を得る。ノード数少・メモリ節約の両立ができる設計で、現在は別方式に移行している(詳細は本記事のスコープ外)。
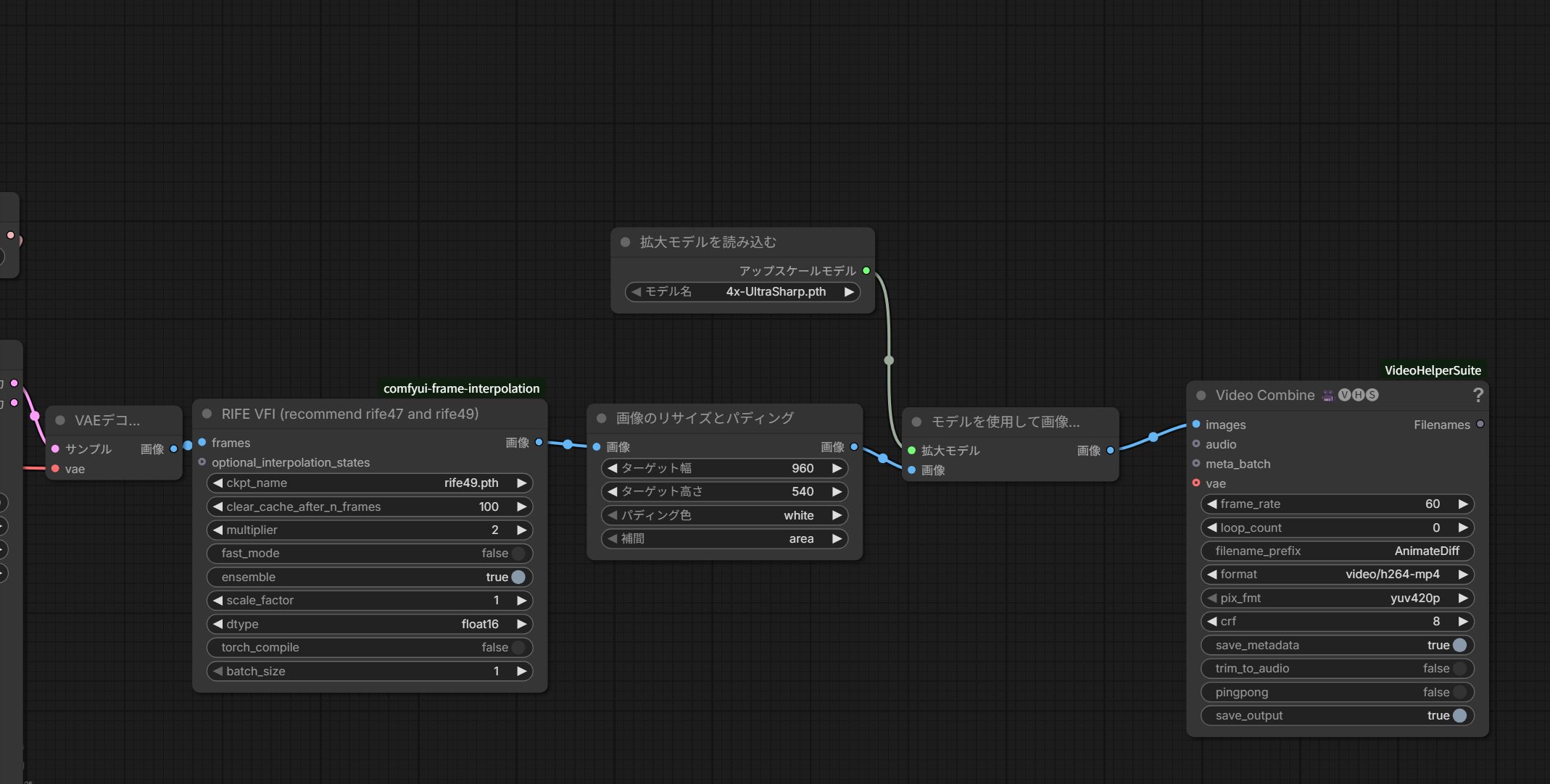
ノード構成(5ノード程度)
- VHS_LoadVideoPath: 入力動画(記事2のcrf=0中間mp4)を読み込み、フレーム列に分解
- ResizeAndPadImage(プリリサイズ): target_width=960, target_height=540, interpolation=area または lanczos(同じ16:9アスペクトへのリサイズなので padding_color は画像に反映されない。念のため black か white を選んでおけばOK)
- UpscaleModelLoader:
4x-UltraSharp.pthを読込 - ImageUpscaleWithModel: 4倍にアップスケール(960×540 → 3840×2160)
- VHS_VideoCombine: 60fps h264-mp4 で書き出し(crf=8〜16)
なぜ「プリリサイズ→4倍アップ」の順なのか
ポイントはメモリ消費の抑制である。4x-UltraSharpなどのアップスケール処理は、入力解像度が大きいほど二次関数的にVRAM・システムRAM消費が増える。
- 悪い例: 1024×576を直接4倍 → 4096×2304 → さらに3840×2160へリサイズ
途中で4096×2304の巨大バッファを保持するためメモリ圧迫、処理も二重 - 良い例(方法A): 1024×576を960×540にプリリサイズ → 4倍アップ → 3840×2160(完成)
ピークメモリが下がり、処理もシンプル
実測の結果、筆者環境(RTX 5080 + RAM 96GB)で ピーク時のシステムRAM使用量は60GB超に達することを確認した(241フレーム分のバッファ + 3840×2160 の出力バッファ + モデル常駐)。しかも処理時間経過と共に単調増加する挙動で、10分を超えてもRAM消費は伸び続ける。32GB RAM環境ではフル構成(60fps・241フレーム・4K)での運用は厳しい(スワップ多発で処理時間が大幅に伸びる)。軽量化の工夫が必須となる(後述)。
フル構成(3840×2160 / 60fps / 241フレーム)は32GBでは厳しいが、以下のいずれかを組み合わせれば運用可能:
- フレームレートを下げる: 60fps → 24fps または 30fps(RIFE VFIの補間を外す、または倍率を下げる)
- フレーム数を減らす: 241フレーム → 97〜121フレーム(動画長を8秒→3〜4秒に短縮)
- 解像度を下げる: プリリサイズをさらに小さく(例: 640×360 → 4倍 = 2560×1440の2.5K止まり)
この3軸のどれかを妥協すれば32GBでも動く。商用量産(長尺・60fps・4K)を目指すなら64GB以上を強く推奨、余裕を見るなら96GB。
この方法の特徴
- メリット: プリリサイズで4Kジャスト・メモリ節約の両立。ノード数も少ない
- 処理時間: 約8秒動画で数分/本(RTX 5080・241フレーム構成)。実測環境により変動あり、crf値やH264エンコード設定で時間が大きく変わるため具体数値は参考程度に
- VRAM使用量: 9〜10 GB 前後(実測Peak 8,981 MB)
- ピークRAM: 実測で60GB超(241フレーム全てを処理中にRAMに保持するため、処理時間経過と共にほぼ単調増加)
- 品質: 標準的。ストック素材用途で十分通用するレベル
方法Aの実測ベンチマーク結果(RTX 5080)
本記事執筆時点(2026年4月)で方法Aを追試した実測結果を公開する。入力は記事2のワークフローで生成した1024×576・60fps・241フレームのmp4。計測は10分のタイムアウト設定で打ち切っているため「完了時間」ではなく「10分時点での状態」を示す点に注意。
| GPU | NVIDIA RTX 5080(VRAM 16GB) |
|---|---|
| システムRAM | DDR5 96GB |
| ComfyUI設定 | --normalvram --bf16-unet --bf16-text-enc |
| 入力 | 1024×576 / 60fps / 241frames / mp4(crf=8) |
| ワークフロー | VHS_LoadVideoPath → ResizeAndPadImage(960×540) → 4x-UltraSharp → VHS_VideoCombine |
| 出力 | 3840×2160 / 60fps / 241frames mp4(crf=8) |
リアルタイム計測ログ(抜粋)
| 経過時間 | VRAM使用量 | RAM使用量(総計) | 状態 |
|---|---|---|---|
| 0秒(開始前) | 1,163 MB | 22,231 MB(22 GB) | ベースライン |
| 8秒 | 1,159 MB | 26,492 MB(26 GB) | 動画読込中 |
| 26秒 | 8,978 MB | 29,629 MB(29 GB) | 4x-UltraSharp モデルロード完了 |
| 115秒 | 8,975 MB | 35,173 MB(35 GB) | アップスケール処理中 |
| 239秒 | 8,975 MB | 43,142 MB(43 GB) | 処理継続中 |
| 373秒 | 8,975 MB | 51,631 MB(51 GB) | 処理継続中 |
| 515秒 | 8,972 MB | 59,087 MB(59 GB) | 処理継続中 |
| 604秒 | 8,972 MB | 64,671 MB(65 GB) | 10分タイムアウト時点、VHS_VideoCombineのH264エンコード中と推定 |
読み取れること
- VRAM は 9 GB 程度で安定: アップスケールはフレーム単位処理のため、LTX 1生成時(12 GB)より軽い。16GB VRAMには余裕がある
- RAM は時間経過と共に単調増加: 241フレーム全てを最終mp4書き出しまで保持する挙動で、10分間で約+42 GB 増加
- 処理時間の計測は参考程度: 本ベンチは10分でタイムアウト設定に達したが、これは筆者側のベンチスクリプトの制限で、実際の方法Aワークフローは通常もっと短時間で完了する(ユーザー運用では数分オーダー)。本記事の時間計測は信頼性を保証しないため、実際の所要時間は各自の環境で確認してほしい
- RAM ピーク 60 GB超は確実: タイムアウト時点で65 GB、完了までに更に数 GB 増える見込み
【方法B】2段階法(潜在空間アップスケール経由・筆者は非採用)
潜在空間でのアップスケールを挟んで細部を追い込む2段階アプローチ。理屈としてはVAEEncode→LatentUpscale→VAEDecodeを経由することで単純な4倍アップにはないディテール生成が期待できる。
ただし筆者はこの方法を試した結果、LTX 1出力との相性が良くなく採用を見送った。特にSD(Stable Diffusion)系のLatentUpscaleを通すと、LTX 1特有の動画のフレーム間一貫性が崩れる傾向があり、ストック素材としての仕上がりでは方法A(プリリサイズ→4倍アップ)の方が安定して品質が出た。
以下は参考情報として構成を示すが、筆者が過去に運用ではない点を踏まえて読んでいただきたい。
ノード構成(11〜13ノード)
- VHS_LoadVideoPath: 入力動画読み込み
- ResizeAndPadImage(プリリサイズ): 入力をいったん中間解像度にパディング付きで整える
- VAEEncode: 画像を潜在空間(Latent)に変換
- LatentUpscale: 潜在空間でアップスケール。中間解像度の2倍程度
- VAEDecode: 潜在空間から画像に戻す
- UpscaleModelLoader:
4x-UltraSharp.pthまたはRealESRGAN_x4plus.pth - ImageUpscaleWithModel: 画像空間で超解像化
- ResizeAndPadImage(4K調整): 3840×2160 にlanczosで整える
- FILM VFI(任意): フレーム補間をさらに強化
- VHS_VideoCombine: 60fps h264-mp4 で最終書き出し
潜在空間アップスケールの考え方と実際の相性問題
理論的には、通常のImageUpscaleWithModel(方法A)は画像そのまま4倍に引き伸ばすので、元の情報量以上のディテールは作られない。一方VAEEncode → LatentUpscale → VAEDecodeの経路を挟むと、潜在空間での補間が走り、その後のアップスケーラーが「情報を追加しながら拡大する」ように働く、というのが一般的な解説。
ただしLTX 1の動画出力との相性は実測では良くなかった。具体的には以下の課題を確認している。
- フレーム間一貫性の崩れ: VAEEncode/Decode を通すと、各フレームで微妙に異なる「解釈」が走り、動画全体として見たときにチラツキ感が出やすい
- SD系VAEとLTX 1出力の学習データの差: Stable Diffusion向けに学習されたVAEは、LTX 1の動画フレームの特徴と完全に噛み合わない場合がある
- 処理時間の割に効果が薄い: 方法Aより処理段数が増える分時間が伸びる割に、ストック素材として見たときの品質差が明確に出ない
結論として、画像単体(静止画)での2段階アップスケールとは違い、動画では方法A(プリリサイズ→4倍アップ)のシンプルな構成で十分というのが筆者の結論。方法Bは一般論として知っておく程度で問題ない。
この方法の特徴(参考データ)
- 期待されるメリット: 静止画では細部復元、ただし動画では不安定
- 処理時間: 方法Aより段数が増える分長くなる(具体の実測値は筆者未計測)
- VRAM使用量: 12〜15 GB 前後
- ピークRAM: 50〜60GB前後
- 品質: LTX 1動画との相性面で方法Aに劣る(筆者実測)
- 採用判断: 筆者は非採用。参考情報として構成を示すのみ
【方法C】フォルダバッチ処理法(4K後ダウンスケール・量産運用向け)
方法A・Bは1本ずつ処理する前提。量産時は「今夜のうちに20本を全部4K化したい」といった使い方をしたいことがある。
ComfyUIにはフォルダを指定して中のmp4を1本ずつ自動で読み込みながら順次処理する仕組みが組める。QUEUE系カスタムノードとVHS_LoadVideoPath・FactoryExactVideoRenameを組み合わせる方法で、筆者は実際にこの方式で数ヶ月にわたり動画量産を回していた。ComfyUIコミュニティでもあまり公開例がなく、量産運用を目指す人には貴重な情報。
方法Aとの設計方針の違い: 方法Aは「プリリサイズ→4倍アップ」でメモリ節約を優先する設計だが、方法Cは入力動画をそのまま4倍アップしてから最終的に4K(3840×2160)にダウンスケールする設計。情報量を最大化してからリサイズするため画質的には有利だが、途中で4K超えのバッファを保持するためメモリ消費は方法Aより増える。画質優先vsメモリ節約のトレードオフが発生している点を理解して使い分けると良い。
バッチ処理の全体像
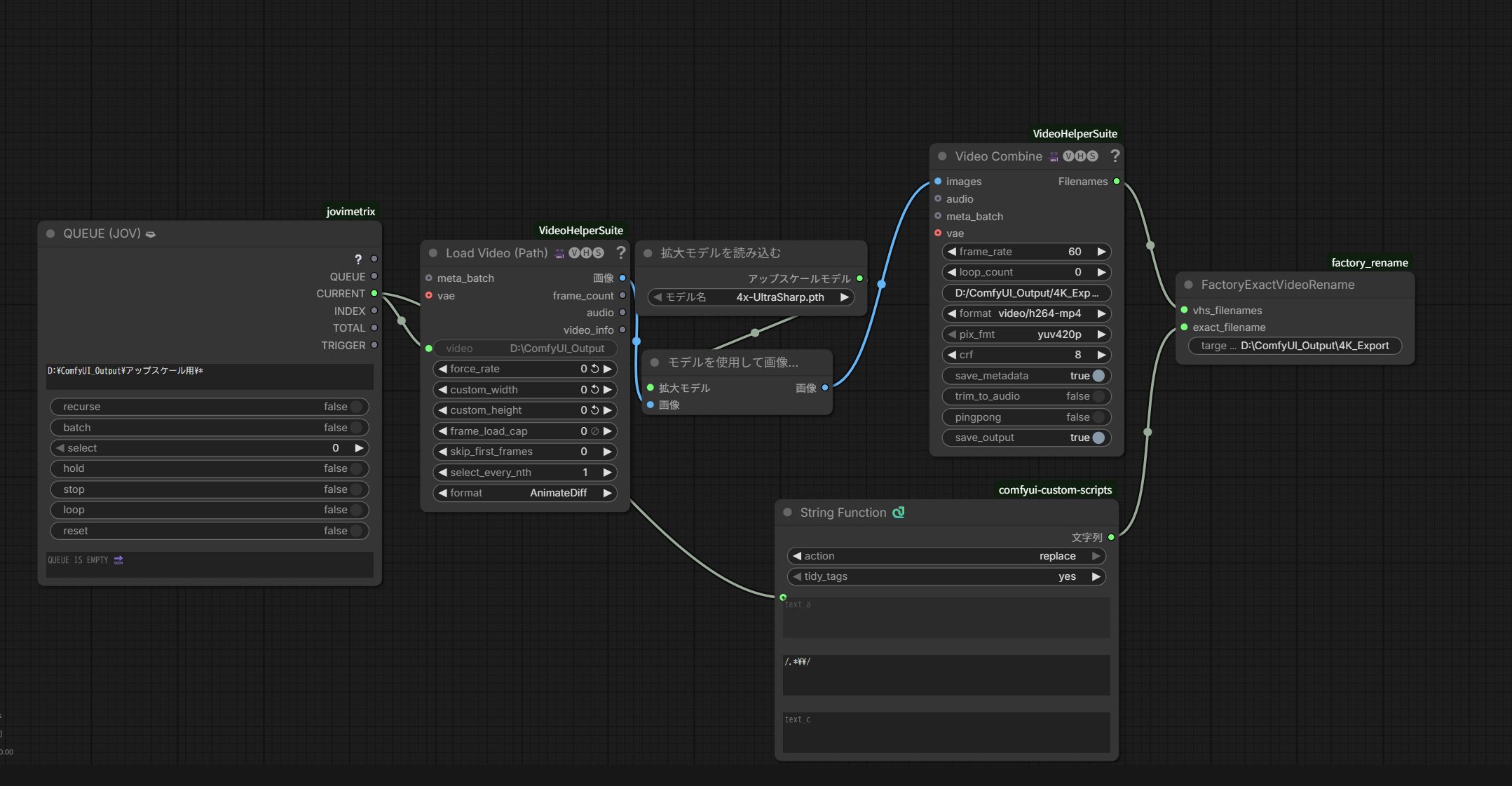
ノード構成と各パラメータ解説(初心者向け)
QUEUE (JOV):フォルダバッチ処理の心臓部
指定したディレクトリ内のmp4を1本ずつ順次処理する「ループ制御」ノード。主要パラメータは以下。
- キュー(対象パス): 例
D:\ComfyUI_Output\アップスケール用\*のように、処理したい動画が置いてあるフォルダをワイルドカード付きで指定 - recurse:
falseなら指定フォルダ直下のみ、trueならサブフォルダも再帰的に対象化 - batch:
falseで1本ずつ処理、trueで複数本をまとめて処理(通常は false 推奨) - select / index:
0で先頭から処理。途中から再開したい時は番号指定 - hold:
false(通常)。true にすると一時停止モード - stop / loop / reset: すべて
falseでOK。ループ無限継続させる場合は loop を true にするが、通常は false
VHS_LoadVideoPath:動画ファイル読込
QUEUE(JOV) から渡される動画パスを受け取り、フレーム列に変換する。主要パラメータ:
- video: QUEUE(JOV)から動的に渡されるため、このノード単体では空欄でもOK
- force_rate:
0で元動画のfpsを維持。30等を指定すると強制的にそのfpsに揃える - custom_width / custom_height:
0で元解像度維持。任意解像度にリサイズしたければ指定 - frame_load_cap:
0で全フレーム読込。短尺テスト時は60等で制限可能 - skip_first_frames:
0(通常)。動画の冒頭数フレームを無視したい時に指定 - select_every_nth:
1で全フレーム。2にすると1フレーム飛ばしで読込(低fps化) - format:
AnimateDiffが汎用。特殊な用途でなければこれで問題ない
UpscaleModelLoader + ImageUpscaleWithModel:アップスケール本体
方法A・Bと同じ。model_name に 4x-UltraSharp.pth を指定して4倍化する。
String Function / CR Text系:出力ファイル名の加工
入力ファイル名(例: R11_H_001_DAR_SlowPan_45897.mp4)から拡張子・階層を削り、出力側で扱いやすい名前に整形する。
- action:
replace(文字列置換モード) - tidy_tags:
yes(余計な空白や改行をクリーンアップ) - text_b(正規表現パターン):
/.*\\/のような指定でパスの階層部分を削除。環境に応じて正規表現を調整
FactoryExactVideoRename:出力ファイル名を保持したまま保存
カスタムノード。target_directory に指定したフォルダ(例: D:\ComfyUI_Output\4K_Export)に、入力と同じファイル名で書き出す。これにより元動画と4K版の対応関係が崩れず量産管理しやすい。
VHS_VideoCombine:最終mp4書き出し
方法Aと同じ。frame_rate: 60 / format: video/h264-mp4 / pix_fmt: yuv420p / crf: 8。save_output: true で保存する設定。
この方法の強み
- 完全自動化: ディレクトリに動画を放り込んでワークフローを実行すれば、全ファイルが順次処理される
- 夜間バッチ運用: 就寝前にキュー実行、朝には全部アップスケール済み
- ファイル名の整合: 入力と出力のファイル名を保ったまま一括処理(Adobe Stock投稿時にメタデータ管理しやすい)
- 画質が高い: 「4倍フル解像度で処理してから4Kにダウンスケール」する設計のため、プリリサイズ先行版より情報量が豊か(メモリとのトレードオフ)
メモリ節約のTips: 方法Aのプリリサイズを方法Cに組み込む
方法Cは画質優先の設計だが、もし「バッチ処理の自動化は欲しいが、メモリ消費を抑えたい」場合は、方法Aで紹介したプリリサイズノード(ResizeAndPadImage)をImageUpscaleWithModelの前に挟むことで、方法Aと同等のメモリ節約効果を得られる。
- VHS_LoadVideoPath → ResizeAndPadImage(960×540) → ImageUpscaleWithModel(4x) → VHS_VideoCombine の流れ
- 4倍で3840×2160(4Kジャスト)に直接到達するため、途中で4K超えバッファを持たずに済む
- 画質面は方法C本来の設計より一段落ちるが、RAM 64GB以下の環境でバッチ処理したい場合の妥協点として有効
つまり「方法Cの枠組み(フォルダバッチの自動化)」と「方法Aの設計(プリリサイズ→4倍アップ)」を組み合わせるハイブリッド構成。メモリと画質のバランスを環境に合わせて調整する考え方を身につけると、運用の幅が広がる。
バッチ処理特有の注意点
- 途中で失敗すると全体が止まる: VRAM不足等で1本目で落ちると後続も処理されない。入力動画の解像度・長さは揃えておく
- VRAM断片化: 長時間バッチで VRAM が断片化することがある。起動時の
PYTORCH_CUDA_ALLOC_CONF設定で緩和可能 - 温度管理: 連続稼働でGPU温度が上がる。室温・ケースエアフロー・場合によっては休憩を挟む
入力動画のダウンスケールをどのタイミングでやるか
「アップスケール前に一度解像度を落とす」のは、上記の方法A冒頭で説明した通りメモリ節約・4Kジャスト調整の両方に効く。タイミングの選択肢は3つ。
選択肢1: ComfyUI内でダウンスケール(方法A・Bで採用)
ComfyUI のResizeAndPadImageノードでワークフロー内でダウンスケールする。
- メリット: 1つのワークフローで完結、ファイル管理がシンプル、本記事の方法A/Bがこれ
- デメリット: ComfyUI のリサイズ処理がボトルネックになる場合がある
- 向くケース: 単発処理で、前処理も一括管理したい時
選択肢2: FFmpegで事前にダウンスケール → ComfyUIで4K化
事前にFFmpegで入力動画を960×540に落としておき、その後でComfyUIに流して4倍アップ。
- メリット: FFmpegは動画リサイズに最適化されていて高速。ComfyUI側の処理時間とメモリを節約
- デメリット: 2段階運用でワークフロー管理が増える
- 向くケース: バッチ処理で全体スループットを上げたい、事前処理を分離したい
選択肢3: 4K化後にダウンスケール(画質優先・メモリ次第)
1024×576を直接4倍 → 4096×2304 → 3840×2160にリサイズ。本記事の方法C(フォルダバッチ処理法)がこの順番。
- メリット: 情報量を最大化してからリサイズするため画質的に有利(高周波ディテールが潰れにくい)
- デメリット: 途中で4Kを超えるバッファ(4096×2304 × 241フレーム分)を保持するためメモリ消費が方法Aより増える。crf=0 / 60fps の書き出し時も負荷大
- コメント: 「書き出せるだけのシステムRAMが確保できるか」が採用判断の分かれ目。RAM 64GB以上(できれば96GB)あれば、画質優先でこの順番を選ぶ価値がある。32GB環境では厳しい。
ComfyUI起動コマンド例(アップスケール用)
アップスケールはモデルをVRAMに常駐させた方が速度が出る。--highvram モードを推奨。
@echo off
setlocal
cd /d "%~dp0"
echo ===================================================
echo [ ComfyUI for 4K Upscale ]
echo ===================================================
.\python_embeded\python.exe -s ComfyUI\main.py ^
--windows-standalone-build ^
--highvram ^
--reserve-vram 2.0 ^
--bf16-unet ^
--preview-method taesd
pause出力ディレクトリ・ポート番号・使用GPUなどの環境依存オプションは各自の構成に合わせて追加する。
最終出力の設定(VHS_VideoCombine)
- frame_rate: 60(RIFE補間後の60fps)
- format:
video/h264-mp4 - pix_fmt:
yuv420p(互換性重視、Adobe Stock推奨) - crf: 8〜16(最終提出用の品質値、画質とファイルサイズのバランス)
方法A/B/Cの使い分けまとめ
| 観点 | 方法A(プリリサイズ1段階) | 方法B(2段階品質) | 方法C(フォルダバッチ) |
|---|---|---|---|
| 処理時間 | 数分/本 | 数分+α/本 | 本数×数分 |
| 品質 | 標準 | 高 | 標準 |
| 学習コスト | 低 | 中 | 中〜高 |
| VRAM | 10〜14 GB | 12〜15 GB | 10〜14 GB |
| ピークRAM(実測) | 60GB超 | 60〜70GB想定 | 60GB超(1本あたり) |
| 必要RAM | 64GB以上推奨 | 64GB以上推奨 | 64GB以上推奨 |
| 向いているケース | 単発・初心者・メモリ節約したい(筆者は過去に使用) | 参考情報(筆者は相性問題で非採用) | 量産・夜間バッチ・画質優先(筆者は過去に使用) |
つまずきやすいポイント
1. 入力動画のcrf値が高い
入力のmp4がcrf=23等で圧縮済みだと、アップスケール時にブロックノイズが拡大される。記事2のワークフローでcrf=0の可逆圧縮で中間mp4を出しておくこと。
2. プリリサイズのサイズを間違える
プリリサイズは960×540(4倍で3840×2160にぴったり)が推奨。512×512のような正方形に設定すると4倍しても2048×2048で16:9にならない。4x-UltraSharpは入力サイズをそのまま4倍するので、事前にジャストサイズを狙う。
3. RAM 32GBで処理が止まる / 異常に遅い
スワップが発生している可能性大。タスクマネージャでメモリ使用量を確認し、50GBに迫っているようなら短尺化・低fps化で回避。本構成は64GB RAM以上が前提。
4. バッチ処理で1本目が落ちると全体停止
QUEUE系はエラー耐性が限定的。バッチ前に方法Aで1本だけ試して動作確認してから、フォルダに残りを入れてバッチ実行するのが安全。
5. アップスケールモデルファイルがない
ComfyUI本体には4x-UltraSharpもRealESRGANも同梱されていない。手動で models/upscale_models/ に配置する必要がある。
まとめ:LTX 1 → 4K出力の全体像
LTX 1で動画を商用量産する場合、最終的なAdobe Stock提出ファイルまでの流れは以下の3段構成。
- LTX 1で生成: 1024×576 / 241frames / 30fps(記事2、RTX 5080で約5分/本の実測値)
- RIFE VFI で60fps化 + 中間mp4(crf=0)書き出し: 記事2内で完結。ここで1024×576・60fps・約8秒の中間ファイルが完成
- プリリサイズ→4倍アップで4K化 + 最終mp4(crf=8〜16)書き出し: 本記事で3840×2160・60fps・約8秒のAdobe Stock最終提出ファイルを作る(方法A・B は単発処理、方法C はバッチ。所要時間は環境依存
1本あたりの所要時間は環境とエンコード設定で大きく変動するため、各自の環境で実測確認を推奨する。ピークシステムRAMは60GB超に達する実測結果を得た。しかも241フレーム構成ではRAM使用量が処理時間と共に単調増加する挙動のため、RAM 64GB以上が推奨(余裕を見たい場合は96GB)。32GB環境では軽量設定(短尺・30fps・低解像度)で運用する工夫が必要。
方法Aで全体フローを固め、量産フェーズになったら方法C(フォルダバッチ処理)へ展開するのが現実的な流れ。本記事の方法A・Cはいずれも筆者が過去に運用していた構成で、現在はさらに別の方式へ移行している。方法B(潜在空間アップスケール)は理論としては興味深いもののLTX 1動画では筆者実測で相性問題があり、深追いは不要。シリーズ3記事を参照しながら、16GB VRAMでのAdobe Stock動画量産を開始していただきたい。
出典・参考
- Lightricks/LTX-Video 公式リポジトリ (GitHub) — LTX-Video の公式実装。 モデル仕様・推論スクリプト・対応フォーマットを確認できる一次情報源
- xinntao/Real-ESRGAN 公式リポジトリ (GitHub) — 4K アップスケールに使用する Real-ESRGAN の公式実装。 学習済みモデルと推論手順の根拠
- Adobe Stock 動画コントリビューター要件 (Adobe 公式 helpx) — Adobe Stock 動画の解像度 (1920px〜4096px) ・尺 (5〜60 秒) ・品質基準の一次仕様
本記事は AIハードウェア図鑑 編集部 が記載時点の情報をもとに執筆。製品アップデートや第三者ベンチマーク・価格・対応ランタイム等の変動で評価が変わる可能性がある。一定期間経過した内容は再検証を推奨する。

