
LTX 1 は Lightricks 社が公開している軽量動画生成 AI モデル (2B パラメータ) で、VRAM 16GB クラスの GPU で商用量産可能な現実解に位置づけられる。出典: Lightricks 公式 LTX Video モデルページ / Hugging Face Lightricks/LTX-Video モデルカード
LTX 1 そのものの概要・モデル選び・入門的な使い方は姉妹サイト「AI ツール図鑑」の LTX Video とは? AI 動画生成の特徴・使い方・必要スペックで解説している。本記事はその実測データ編として位置づけており、合わせて読むと理解が深まる。
- RTX 5080: 1 本 5 分 9 秒 (309 s)、Peak VRAM 15.9 GB、Peak RAM +25.9 GB (筆者実測 / nvidia-smi 計測)
- RTX 5060 Ti (Oculink): 1 本 9 分 12 秒 (552 s)、Peak VRAM 16.0 GB、Peak RAM +27.2 GB (筆者実測)
- 上記は LTX 1 本体 + RIFE VFI 補間までの時間。4K アップスケール処理は別工程で追加時間が必要
- LTX 2.3 (22B AV 版) は標準 loader で読めず、VRAM 16GB での商用量産は現時点で非現実的
- 筆者の運用実績: 3 ヶ月で 928 本生成 → 約 30% を Adobe Stock にアップロード → 審査採用率 45.7% (直近 4 日、Adobe Stock 公式審査結果メール由来)
この記事で検証した範囲
本記事は RTX 5080 (VRAM 16GB) および RTX 5060 Ti 16GB (Oculink 接続) で LTX 1 を筆者の本番ワークフローで実測した一次記録である。ComfyUI 上で 1024×576 解像度・241 フレーム・50 ステップ・RIFE VFI (フレーム補間 x2)・H264 mp4 出力という、Adobe Stock 向け素材生成の前段と同じ構成で測定した。出典: ComfyUI 公式 (Comfy.Org) / RIFE 公式 GitHub (megvii-research/ECCV2022-RIFE)
結論を先に言えば、16GB VRAM で動画生成を商用量産するなら LTX 1 が現実解である。LTX 2.3 は最新だが VRAM 16GB 環境では安定した量産ラインを築けない。
検証環境
| 項目 | 構成 |
|---|---|
| メイン GPU | NVIDIA RTX 5080 (VRAM 16GB GDDR7、PCIe 5.0) |
| サブ GPU | NVIDIA RTX 5060 Ti 16GB (Oculink 経由 / MINISFORUM DEG1) |
| CPU | Intel Core i7-14700F |
| システム RAM | DDR5 96GB |
| ストレージ | NVMe SSD 2TB x 2 |
| OS | Windows 11 |
| ComfyUI | v0.9.1 (embedded Python 3.12 / PyTorch 2.9.1+cu128) |
| 運用モデル | ltx-video-2b-v0.9.1.safetensors (LTX 1) |
| テキストエンコーダ | t5xxl_fp16.safetensors |
| 後処理 | RIFE VFI v4.9 (rife49.pth) フレーム補間 x2 (30fps → 60fps) |
| 検証日 | 2026 年 4 月 17 日 |
出典: 筆者環境のセットアップ実機 / Hugging Face Lightricks/LTX-Video / RIFE 公式リリース (v4.9)
LTX 各バージョンのファイルサイズ実測
| モデル | サイズ | 位置付け |
|---|---|---|
| ltx-video-2b-v0.9.1 (LTX 1) | 5.72 GB | 軽量・高速。16GB VRAM で余裕動作。筆者の運用モデル |
| ltxv-13b-0.9.7-distilled-fp8 | 15.69 GB | 13B 蒸留 fp8。16GB でギリギリ |
| ltx-2-19b-dev-fp8 | 27.08 GB | 19B dev fp8。オフロード必須 |
| ltx-2.3-22b-distilled-fp8 (AV) | 29.53 GB | 最新の音声付き。標準 loader 非対応 |
各サイズは筆者環境で safetensors ファイルを直接 ls した実値で、Hugging Face Lightricks 組織ページの各モデルカードに記載のサイズと一致する。出典: Hugging Face Lightricks 組織ページ (2026-04 確認)
RTX 5080 vs RTX 5060 Ti 比較 (同一ワークフロー)
1024×576、241 frames、50 steps、cfg 3.0、RIFE VFI x2 の同一設定を両 GPU で実行した。本記事では RTX 5080 は bf16、RTX 5060 Ti は fp8 量子化モードで測定しているが、両 GPU とも bf16 / fp8 のいずれでも動作する。
1 本生成にかかる時間・VRAM・RAM 消費
| 項目 | RTX 5080 (16GB) | RTX 5060 Ti 16GB (Oculink) | 差 |
|---|---|---|---|
| 総生成時間 | 309 秒 (5 分 9 秒) | 552 秒 (9 分 12 秒) | 5060 Ti が 1.79 倍遅い |
| Peak VRAM | 15,890 MB | 16,004 MB | ほぼ同じ (どちらも枠一杯) |
| Peak RAM 使用増 | +25.9 GB | +27.2 GB | 5060 Ti がやや多い |
| 測定時 ComfyUI 設定 | --normalvram --bf16 |
--normalvram --fp8_e4m3fn |
どちらも bf16 / fp8 いずれでも動作可能 |
| 接続 | PCIe 5.0 x16 (内部) | Oculink (PCIe 4.0 x4 相当) | 帯域差が大きい |
出典: 筆者実機 nvidia-smi / Windows パフォーマンスモニタ計測値 (2026-04-17)
読み取れること
- 生成時間差は約 1.8 倍。RTX 5060 Ti + Oculink は本体内蔵 RTX 5080 の約 56% の速度
- VRAM 使用量は両方ほぼ 16GB 満載。RIFE VFI のフレーム補間段階で枠一杯に達する
- bf16 でも fp8 でも動く。精度・速度のトレードオフで選択可能
- Oculink 経由でも運用可能。時間はかかるが本体内蔵と同じ品質・同じワークフローで完走する
- 初回モデルロードで Oculink 帯域がボトルネックになり、ロード時間が本体より長い
- 推論開始後は VRAM 内処理が中心なので帯域差の影響は小さい
- 長時間稼働時の Oculink ドック電源 (DEG1 の場合 750W 専用 PSU) と GPU 温度管理が重要
本記事の実測時間に含まれない処理 (重要)
上記の「5 分 9 秒」「9 分 12 秒」はLTX 1 の動画生成 + RIFE VFI フレーム補間 + H264 エンコードまでの時間である。筆者の実運用では、この後段に4K アップスケール処理が続き、そちらでもまとまった時間がかかる。
Adobe Stock への最終提出ファイル (4K 60fps mp4) を作るなら、本記事の時間に加えて 4K アップスケール処理時間が乗る想定で運用計画を立てる必要がある。4K アップスケールの具体的な構成と時間は、続編記事 (記事 3) で別途扱っている。
フェーズ別 VRAM / RAM / 時間 (RTX 5080 詳細)
| フェーズ | 経過時間 | VRAM 使用量 | RAM 使用増 | 備考 |
|---|---|---|---|---|
| 初期状態 | 0 s | 1,034 MB | 0 | ComfyUI 起動直後 |
| モデルロード | 0-5 s | 10,070 MB | +7.6 GB | LTX 1 + T5-XXL + VAE 読込 |
| LTX 1 生成中 | 5-155 s | 12,124 MB | +6.9 GB | 50 steps・241 frames 生成 |
| RIFE VFI 開始 | 155 s | 15,768 MB | +18.4 GB | フレーム補間処理開始 |
| RIFE VFI 中 | 155-300 s | 15,890 MB (Peak) | +25.9 GB (Peak) | VRAM 16GB 枠ギリギリ |
| mp4 エンコード | 300-309 s | drop | 解放 | H264 crf=0 書出 |
出典: 筆者実機 nvidia-smi 連続サンプリング / Windows タスクマネージャ RAM 推移 (2026-04-17)
16GB を埋めているのは LTX 1 本体ではなく RIFE VFI
計測すると、LTX 1 本体の生成だけなら VRAM は 12 GB で収まっている。16GB 枠を使い切っているのは RIFE VFI のフレーム補間段階で、このフェーズで VRAM が 15.9 GB、システム RAM も +26 GB まで伸びる。RIFE 公式 GitHubでも、補間フレーム数に比例して必要メモリが線形に増えることが README に明記されている。出典: megvii-research/ECCV2022-RIFE README (RIFE v4.9 系統)
16GB VRAM ユーザーが取るべき戦略は複数ある:
- A) フレーム補間なしで運用する (30fps 出力、VRAM は 12 GB で済む)
- B) RIFE VFI を使うが RAM を 64GB 以上確保する (本記事の構成)
- C) ComfyUI 用の PurgeVRAM 系カスタムノード (コミュニティ開発の GPU メモリ強制解放ノード) をノード間に挟む構成にすると、12GB GPU でも動作可能になる
RAM 32GB 環境でも OS・アプリを絞って軽量設定 (24fps・30fps・短尺) にすれば審査通過する作品は生成できるが、本記事のような 60fps 高解像度構成では RAM 64GB 以上を推奨。余裕を見て 96GB 構成が最も安定している。
本番運用の実績: 3 ヶ月 928 本生成、Adobe Stock 採用率 45.7%
同じ RTX 5080 環境で LTX 1 を運用した 2026 年 1 月 〜 4 月の実データである。Adobe Stock 側の数値は同社から受信した審査結果通知メールに基づく。出典: Adobe Stock コントリビューター審査結果通知メール (2026-04-13 〜 2026-04-16 / 個人情報トリミング済画像を本文末に掲載)
実際の流れ (生成 → アップロード → 採用)
筆者の運用は 3 段階で絞り込む構造である。
- LTX 1 で生成: 3 ヶ月で累計 928 本 (2026 年 1 月 〜 4 月、筆者のローカルストレージ集計)
- 検品でアップロード候補を選別: 生成したうち約 30% (おおむね 280 本前後) を Adobe Stock へアップロード
- Adobe Stock 審査を通過: アップロード分のうち直近 4 日のデータで採用率 45.7%
「生成した全本数に対して最終的に商品化される割合」はおおむね全体の 14% 前後 (30% × 45.7%)。Adobe Stock は 2025 年以降 AI 生成素材の審査を厳格化しており、類似品判定 (similar content already in our collection) を受けて不採用になるケースが増えている。Adobe Stock コントリビューター公式ヘルプの生成 AI コンテンツ規約でも 2025 年以降に審査基準の更新が告知されている。この環境下で 45.7% は実用的に使える範囲に収まっている。出典: Adobe Stock 公式 Contributor Help (生成 AI コンテンツ規約)
Adobe Stock 審査結果 (直近 4 日間)
| 提出日 | 採用 | 不採用 | 採用率 |
|---|---|---|---|
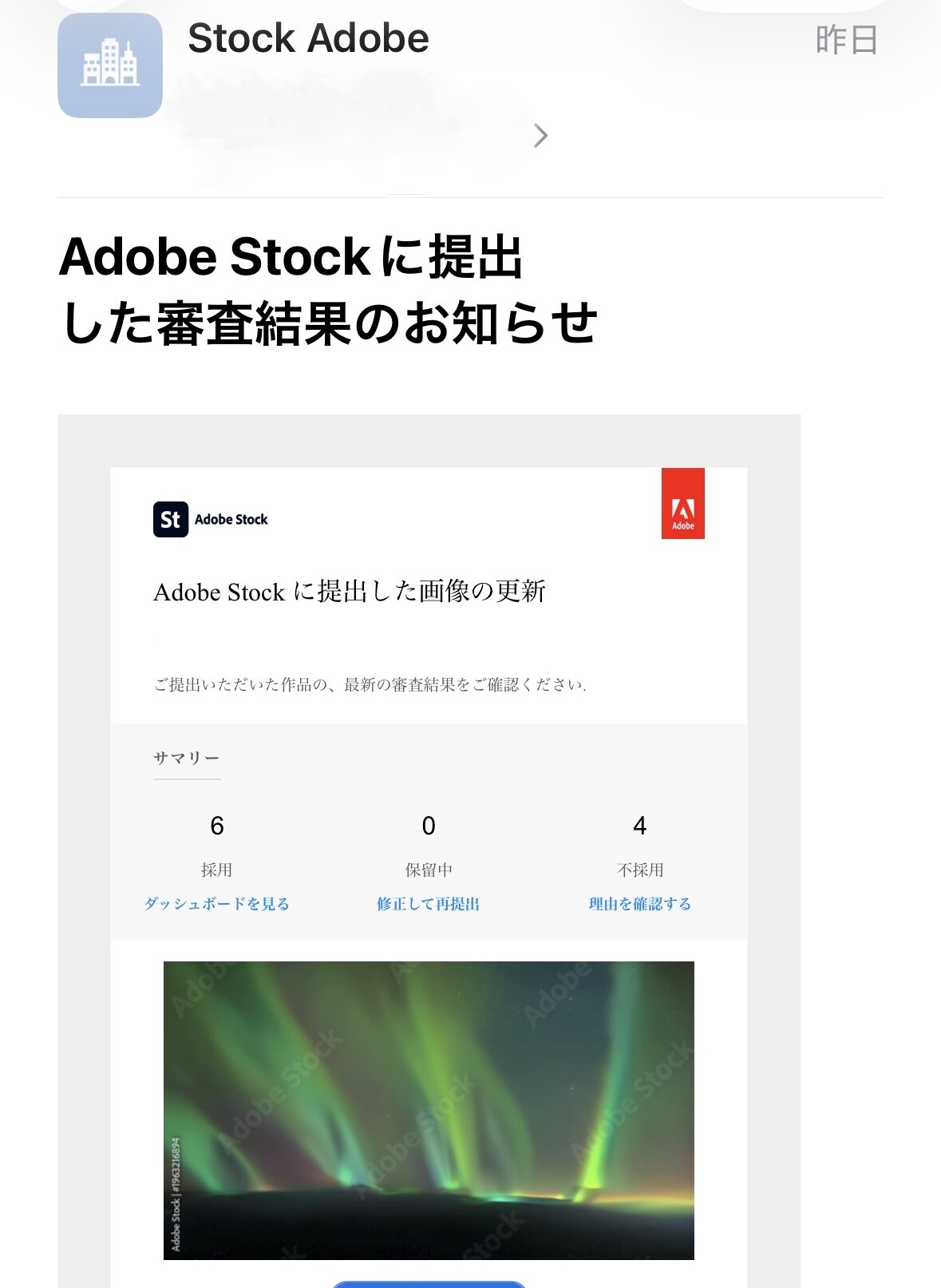
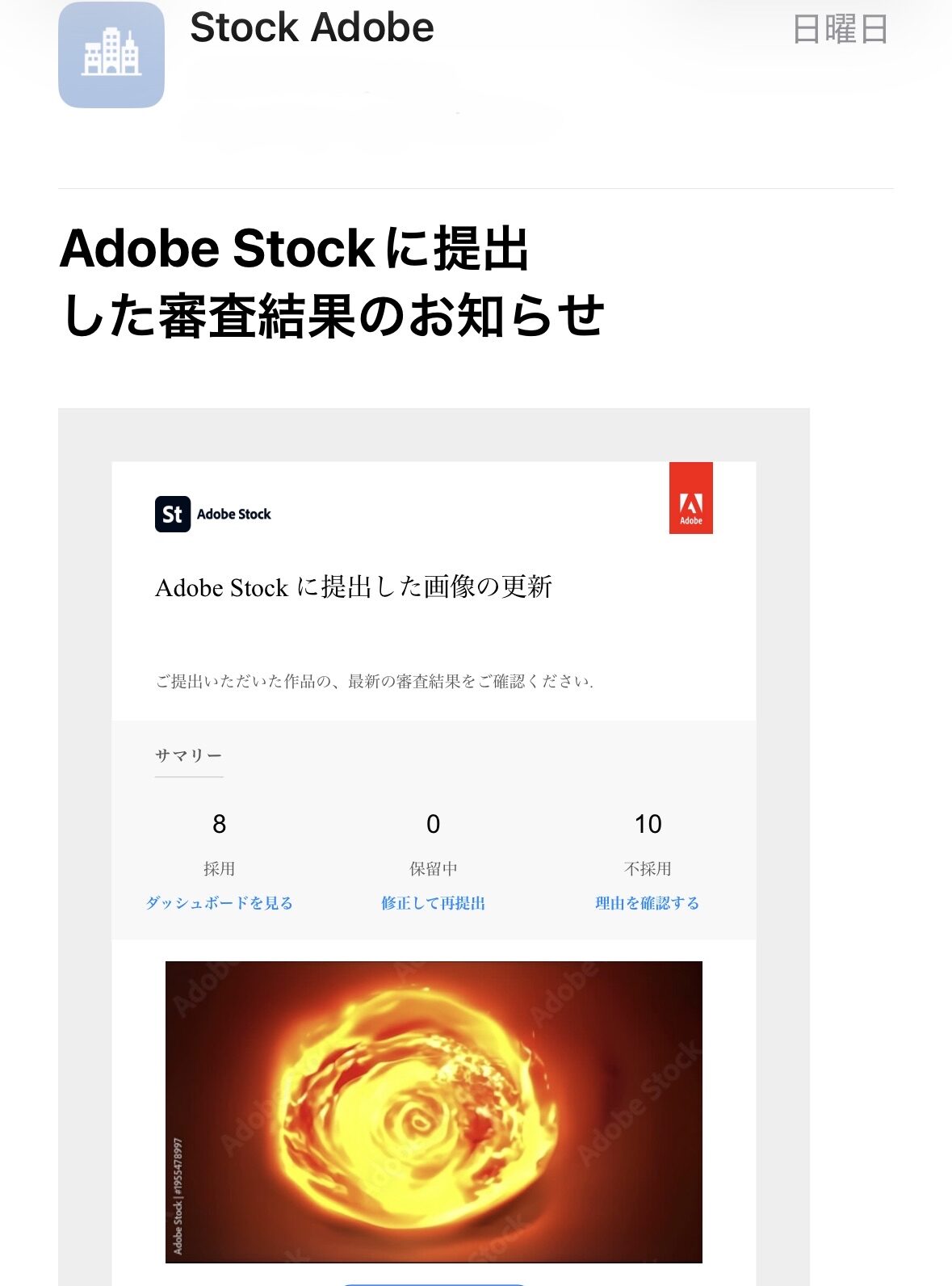
| 2026 年 4 月 13 日 (日) | 8 本 | 10 本 | 44.4% |
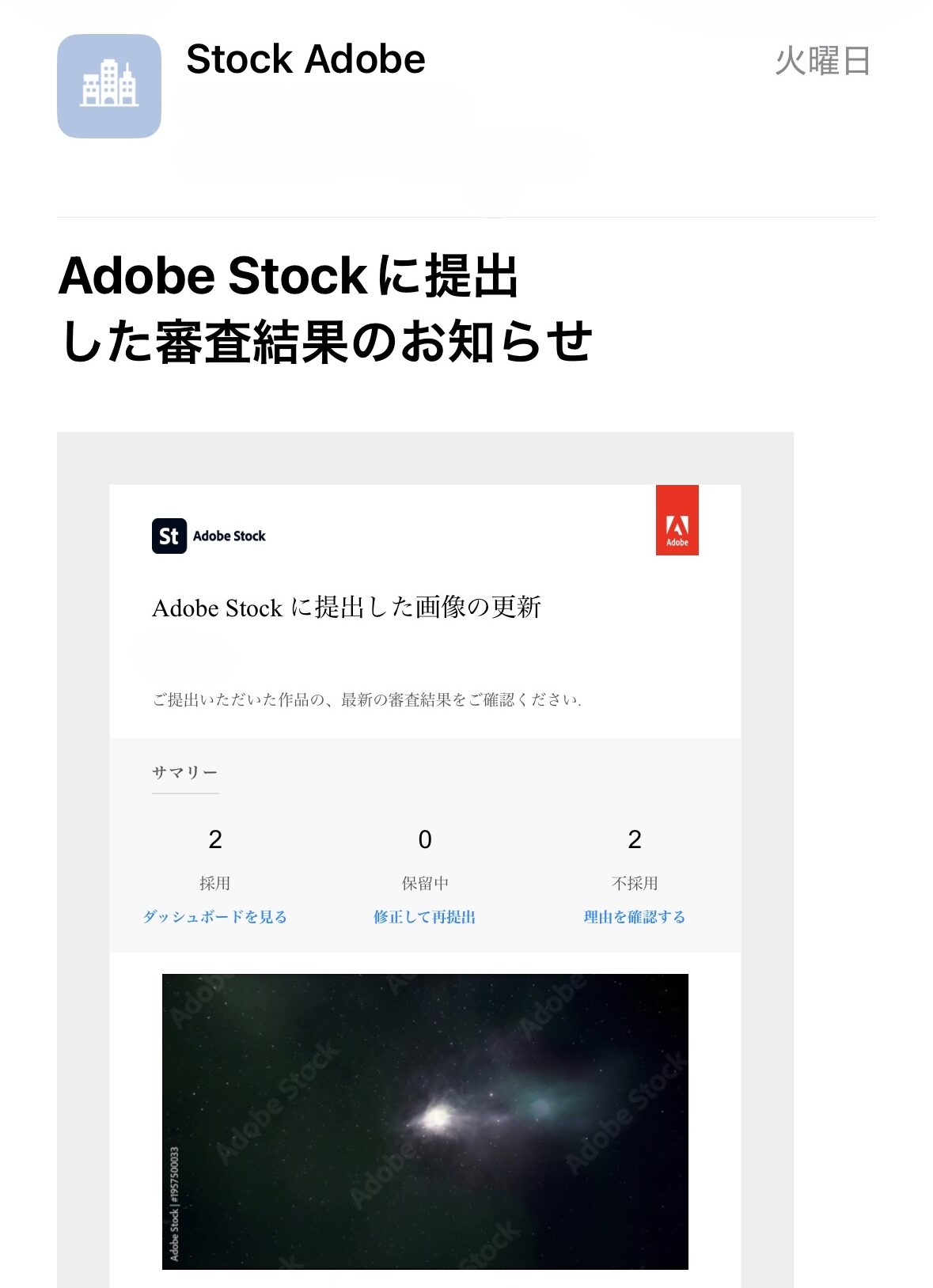
| 2026 年 4 月 14 日 (火) | 2 本 | 2 本 | 50.0% |
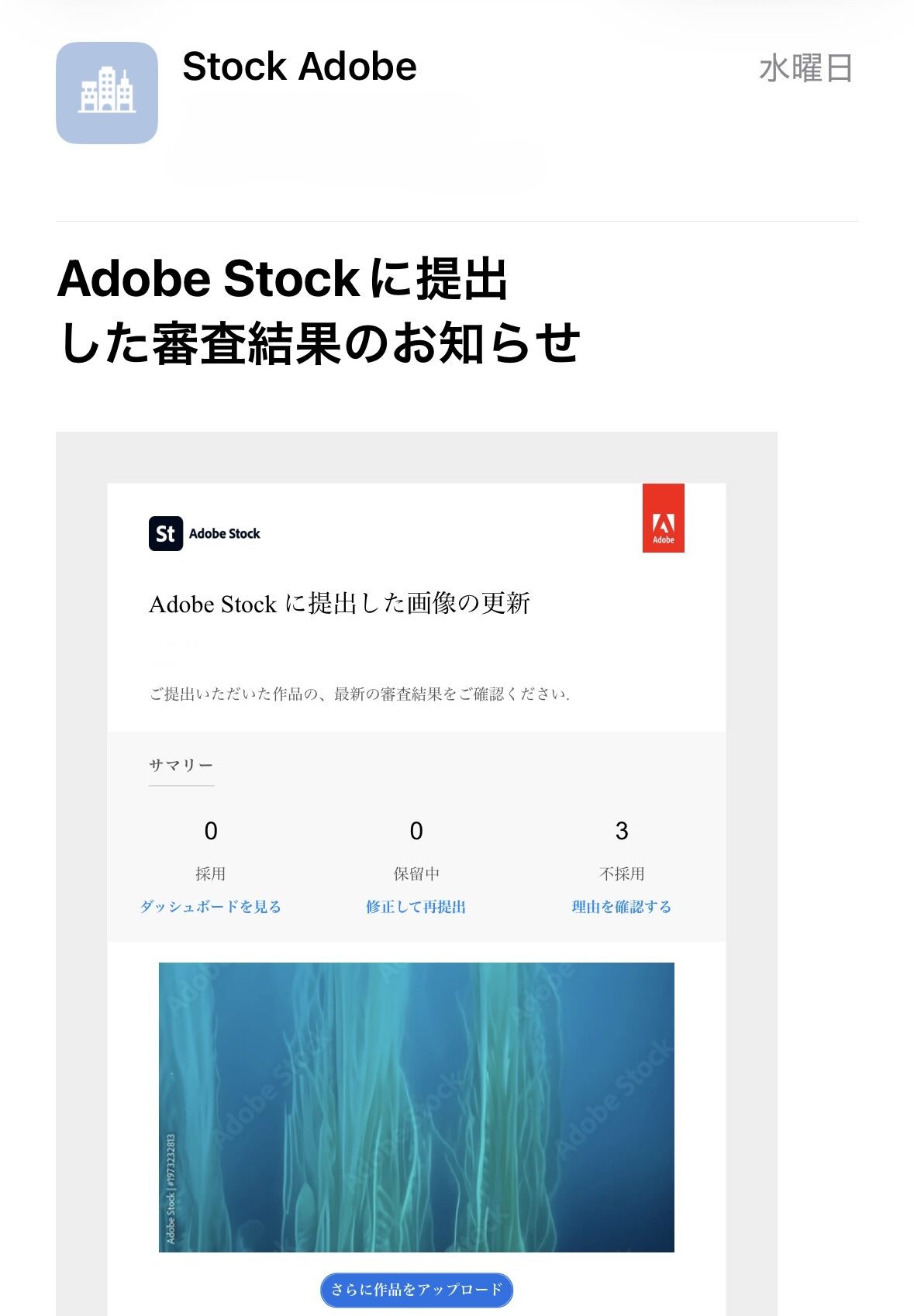
| 2026 年 4 月 15 日 (水) | 0 本 | 3 本 | 0.0% |
| 2026 年 4 月 16 日 (木) | 6 本 | 4 本 | 60.0% |
| 合計 (4 日間) | 16 本 | 19 本 | 45.7% |
出典: Adobe Stock 公式審査結果メール (2026-04-13 〜 2026-04-16、本記事末に証憑画像 4 枚を添付)
1 本分の生成プロンプト例 (本番級・実運用)
参考までに、筆者が Adobe Stock 向け動画 1 本を生成する際に使用している本番級プロンプトを掲載する。一般的に紹介されている「シンプルな 30 語程度のプロンプト」とは別次元の作り込みで、物理現象の英語表現・映画撮影用語・光学パラメータ・ムード指定を高密度に織り込んで LTX 1 の生成品質を引き出している。
下記は Oil Slick Rainbow Macro (虹色薄膜干渉のマクロ映像) 生成時の実プロンプトである。このレベルの作り込みを手動で毎回書くのは非現実的なため、筆者はローカル LLM (Ollama + Gemma 3 12B GGUF) を使ったプロンプト自動生成の仕組みを組んでいる。具体的な生成ロジックは本記事のスコープ外だが、下記のプロンプトはその出力物の 1 つである。
positive prompt
(Iridescent Thin-Film Interference: Oil Slick Rainbow Macro:1.3), (Low angle hero composition, subject rises from bottom edge, expansive upper negative space:1.2), Rainbow Band Drift Sequence, Marangoni convection spreading coefficient, Film drainage velocity gravity, Capillary number viscous-surface ratio, Thin-film equation lubrication, seamless looping motion, first and last frame match, stable camera, temporal coherence, smooth continuous motion, Tripod shot, locked off camera, stable composition, no movement, perfect framing, Central composition, Clear spatial structure, Rack focus shifting from foreground to background. The oil slicks surface flow exhibits Marangoni drift towards the right, with color bands migrating at approximately 1 mms, and interference pattern density increasing by 30 over 8 seconds At reflection angles between 40 to 50, hard directional spotlight, dramatic chiaroscuro, deep black shadows, high contrast, focused beam, Silver White Overexposed, Soft luminous pastel tones, dreamlike bloom and halation, iridescent prismatic nuances, ethereal atmospheric glow, angelic backlit translucency, subsurface scattering illumination, pearl-white highlights, celestial haze, Flat dark surface, Petroleum rainbow film, Oil slick thin-film optics, petroleum film thickness -, thin-film interference bands interference color, thermocapillary surface tension flow, iridescent band migration, angle-dependent structural color, Clear refractive index hydrocarbon film, ambient light iridescence, macro flat surface view, slow drift animation, Dreamlike beauty and weightless fantasy, angelic soft-focus atmosphere, luxury wellness and cosmetic aesthetic, serene relaxation mood. Cinematic 16:9, Widescreen, Anamorphic lens, Petroleum thin-film Marangoni band, Clear refractive index hydrocarbon surface, thin-film interference bands interference color, Angle-dependent structural color gradient, macro lens, 100mm, extreme close-up, shallow depth of field, bokeh, microscopic details,, super slow motion, weightless drift, graceful deceleration, ultra high resolution optics, optimal depth of field, maximum tonal depth, optical realism, diffraction-limited sharpness, zero distortion, sub-pixel detail, pristine optical quality, edge-to-edge sharpness, premium lens coatings, (no text:1.2)negative prompt
(text:2.0), (watermark:2.0), (logo:2.0), (ui:2.0), (hud:2.0), (digits:2.0), (numbers:2.0), (bad geometry:1.5), (amorphous:1.5), (unstructured:1.5), (muddy:1.5), (blurry focus:1.3), (static:1.5), (frozen:1.5), (statue:1.5), (still image:1.5), (solidified:1.3), (motionless:1.5), (grid:1.5), (mesh:1.5), (dots:1.5), (pixelated:1.5), (pattern:1.5), (human:1.5), (face:1.5), (hand:1.5), (skin:1.5), (animal:1.5), (low resolution:1.3), (artifacts:1.3), (morphing:1.5), (shaking:1.5), (flickering:1.5), (glitch:1.2), (sharp edges:1.5), (hard light:1.5), (industrial:1.5), (mechanical:1.5), (oversaturated:1.3), (heavy:1.3), (Pop:1.3), (Burst:1.3), (Dry:1.3), (Dull:1.3), (Matte:1.3), (Grey:1.3), (Black and White:1.3), (Solid:1.3), (Rock:1.3), (Wood:1.3), (Dirty:1.3), (Pollution:1.3), (Drug:1.3), (Trippy:1.3), (Oil pollution:1.3), (Chemical spill:1.3), (Toxic:1.3)LTX 1 はシンプルなプロンプトでも動画を出してくれるが、ストック素材として採用率を維持するには、こうした密度の高い描写指定 + 広範なネガティブ排除が効いてくる。prompt 長は positive だけで 1500 文字超、negative も 500 文字を超える規模である。
プロンプトを LLM に大量生成させる発想 (初期の手動テンプレ例)
ストック素材の量産では、似たようなプロンプトを何本も書き続けると被りが出て審査で類似品判定 (similar content) を受けてしまう。筆者も最初は Gemini Pro のチャット画面に手作業で指示を流し込み、バリエーション違いの動画用プロンプトを一括出力させていた。
以下は当時使っていたテンプレの簡略版である。これをそのまま LLM のチャットに貼り付けて「N 本出力して」と頼むと、LTX 1 に流せるプロンプトが N 本まとめて返ってくる仕組みである。
# LTX 1 動画プロンプト一括生成テンプレ (簡略版) [共通条件] - 生成本数: N 本 (例: 30 本) - 用途: LTX 1 動画生成用の positive + negative プロンプト - 1 本ごとにユニークで、被りを最小化すること [生成テーマの例 - 概ね均等配分] Theme A: 触覚的な物質表現 主題: 高粘性の液体金属、表面張力、微細な泡、サブサーフェススキャタリング 参考語彙: macro cinematography of viscous molten material, tactile density, surface tension, subsurface scattering, anisotropic highlights Theme B: スペクトル光学現象 主題: 光の回折・屈折・分光・減衰・ボケ 参考語彙: abstract spectral energy fluid, volumetric glowing particles, fiber optic light trails, diffraction, anisotropic bokeh Theme C: ミクロ生物物理 主題: 細胞膜・生物発光・有機組織の透過 参考語彙: bioluminescent membrane, organic tissue transparency, electron microscope aesthetics, subsurface scattering in organic matter [共通末尾タグ (positive 末尾に毎回追加)] (black background:1.3), (best quality, 4K, uhd:1.2), ultra-detailed, (seamless loop:1.3), (smooth motion:1.2) [共通ネガティブ (negative 側に必ず入れる)] (no humans, no face, no hand, no bad anatomy:2.0) (no text, no watermark, no logo:2.0) (no architecture, no straight lines, no buildings:1.5) (no distortion, no artifacts, no blurry, no halos:1.5) [出力ルール] - 1 本ごとに positive と negative をセットで出力 - 説明文や挨拶は一切不要、プロンプト本体だけ - Theme A → B → C の順で、指定本数を 3 分割して循環 このテンプレを LLM (Gemini Pro / Claude / ChatGPT / ローカル LLM など) に投げると、1 回のやりとりで 30 〜 100 本の LTX 1 用プロンプトが出てくる。手動で 1 本ずつ考えるより圧倒的に早く、「被らない」という点で量産向きである。
現在の筆者の運用はこの初期テンプレから進化し、ローカル LLM (Ollama + Gemma 3 12B GGUF、Oculink 側の 5060 Ti に常駐) による完全自動化に移行している。軸の切り方・品質チューニング・被り検出など具体の仕組みは本記事のスコープ外としている。
LTX 2.3 が 16GB VRAM で商用量産に向かない 3 つの理由
1. 標準 loader で読み込めない (技術的障壁)
LTX 2.3 蒸留版はLTX AV (Audio-Video 統合)アーキテクチャを採用しており、transformer 内に音声用パラメータが追加されている。ComfyUI-LTXVideo の GitHub READMEでも、AV モデルは専用ノード経由でのみロード可能と明記されている。ComfyUI 標準の CheckpointLoaderSimple では次元不一致で失敗する。出典: Lightricks/ComfyUI-LTXVideo (公式 custom node リポジトリ)
RuntimeError: Error(s) in loading state_dict for LTXAVModel: size mismatch for adaln_single.linear.bias: copying a param with shape torch.Size([36864]) from checkpoint, the shape in current model is torch.Size([24576]).動かすには ComfyUI-LTXVideo カスタムノードを最新化し、LTXVAudioVAELoader、LTXVSeparateAVLatent 等の AV 対応ノードでワークフローを組み直す必要がある。
2. モデルサイズ 29.5GB → 16GB VRAM に収めるにはオフロード必須
ディスク上の fp8 checkpoint で 29.53 GB。16GB VRAM に収めるには大規模な CPU オフロードが必要で、推論速度が大幅に低下する。LTX 1 の 5 分/本 (RIFE VFI 込) に対し、LTX 2.3 のオフロード運用では数十分オーダーになる可能性がある。Hugging Face の LTX-Video-2.3 モデルカードでも、推奨 VRAM が 24GB 以上と記載されている。出典: Hugging Face Lightricks/LTX-Video-2.3 モデルカード
3. チューニングコストが商用 ROI に合わない
LTX 2.3 用の最適ワークフロー構築 (AV ノード配線、VAE 分離、tile 最適化) に数日から数週間が必要となる。筆者は既に LTX 1 で Adobe Stock 採用率 45.7% を達成しており、これを崩して 2.3 へ移行する収益インパクトが見合わない判断である。
16GB VRAM ユーザーへの 3 つの選択肢
選択肢 A: LTX 1 をローカル運用 (筆者の推奨)
LTX 1 (ltx-video-2b-v0.9.1) は 5.72 GB と軽量で、RTX 5080 で 5 分 9 秒/本、RTX 5060 Ti (Oculink) で 9 分 12 秒/本の実測値 (RIFE VFI まで)。商用量産に十分なスペックで、3 ヶ月 928 本生成・Adobe Stock 採用率 45.7% の実績がある。
GPU 選択の目安:
- RTX 5060 Ti 16GB: 新品 10.5 万円前後 (価格.com 最安値・2026 年 4 月時点)。LTX 1 量産の最低コスト入口。本記事の実測モデル
- RTX 5070 / 5070 Ti: 5060 Ti より生成時間が短く、コストと速度のバランスが良い中間帯
- RTX 5080: 20 万円台 (価格.com 最安値・2026 年 4 月時点)。本記事の最速ライン
出典: 価格.com グラフィックボードカテゴリ (2026-04 確認)
選択肢 B: クラウド型動画生成サービス
2026 年 4 月時点、クラウド動画生成は激しい変動期にある。OpenAI Sora は 2026 年 4 月に Web・アプリ版を終了し、API も 9 月で停止予定。代替として以下のサービスが有力である。
- Google Veo 3.1: 4K 60fps・48kHz ネイティブ音声対応 (Google DeepMind 公式)
- Kling 3.0 (Kuaishou): 物理シミュレーション精度が高く、最長 2 分の長尺生成が可能
- Runway Gen-4.5: 映画制作現場での採用例が豊富 (Runway 公式)、カメラワーク制御に強み
- Seedance 2.0: 無料枠があり、コストゼロで始められる
ローカル GPU 不要、月額数千円から数万円。ただし商用ライセンスと AI クレジット表記要件は各サービスで異なるため、Adobe Stock 等に投稿する場合はライセンス条件の確認が必須である。出典: 各サービス公式ページ (2026-04 確認)
選択肢 C: VRAM 24GB 以上の GPU に投資
RTX 3090 (中古 15 万円から)、RTX 4090 (30 万円台)、RTX 5090 (50 万円から)、プロ向け RTX A5000 / A6000。LTX 2.3 の本来の実力を引き出すにはこれが前提となる。出典: 価格.com グラフィックボードカテゴリ (2026-04 確認)
まとめ: 最新を追わず、動く実績モデルで量産する
続編記事として、LTX 1 を ComfyUI で動かすノード構成の全体像と、LTX 1 動画を 4K アップスケールする手順を整備している。記事 2 はノード配線の全体像、記事 3 は 4K アップスケール処理を扱い、本記事 (記事 1) の実測データと合わせて生成 → 補間 → アップスケール → 最終出力の 3 段階を全て確認できる構成にしている。シリーズ全体の最終目標は8 秒・4K (3840×2160)・60fps・H264 mp4の Adobe Stock 投稿用ファイルである。
2026 年 4 月時点、VRAM 16GB の GPU で商用動画量産を目指すなら、最新の LTX 2.3 ではなくLTX 1 (2B 軽量版) が現実解である。
RTX 5080 で 5 分 9 秒/本、RTX 5060 Ti (Oculink) で 9 分 12 秒/本の実測値 (LTX 1 + RIFE VFI)。4K アップスケール工程は別処理で追加時間が必要だが、16GB VRAM 枠にギリギリ収まる水準で商用量産できる。RAM 64GB 以上 (推奨 96GB) を確保すれば安定運用、RAM 32GB でも軽量設定なら審査通過経験あり、12GB VRAM も PurgeVRAM 系カスタムノード併用で運用可能である。
LTX 2.3 を触ってみたい場合は、24GB 以上の GPU に載せ替える以外に、Lightricks 公式の LTX Studio や Fal.ai・Replicate 等のクラウドサービス経由で使う選択肢がある。いずれも従量課金なので、本格導入の前にクラウドで挙動を試してからローカル移行の判断をするのが現実的である。一方、16GB VRAM で今から動画量産を始めるなら、LTX 1 + RTX 5060 Ti 16GB (10.5 万円〜)、または RTX 5080 + RAM 64GB 以上という構成から入るのが無難な選択肢になる。
本記事の情報は記載時点のもの。製品アップデートや第三者ベンチマーク・価格・対応ランタイム等の変動で評価が変わる可能性がある。一定期間経過した内容は再検証を推奨する。
参考資料
- Hugging Face 公式: Lightricks/LTX-Video モデルカード
- GitHub 公式: Lightricks/ComfyUI-LTXVideo (LTX Video 公式 ComfyUI ノード)
- GitHub 公式: megvii-research/ECCV2022-RIFE (RIFE フレーム補間)
- NVIDIA 公式: GeForce RTX 5080 製品ページ
- Adobe 公式: Adobe Stock Contributor 生成 AI コンテンツガイドライン

