ComfyUIで生成を自動化しようとすると、入口はPythonスクリプトやAPI、workflow JSONの直接編集になりがちだ。だが、ComfyUIを使っている人がみなエンジニアというわけではない。ノードはつなげるけれどPythonは読めない、APIも分からない、JSONを手で書き換えるのも気が進まない。そういう人にとって、「自動化したいのにAPIの話になった瞬間に止まる」のはよくある詰まり方である。
ここで紹介するのは、APIもPythonも使わず、ComfyUIのノードと外部テキストだけで生成条件を切り替える方法だ。プロンプトや各パラメータを1行のテキストにまとめ、ComfyUI側でそれを辞書として分解し、各ノードへ配る。この記事ではこの手法を辞書式自動化と呼ぶ。手作業のComfyUIとAPI自動化のちょうど中間に置ける、軽い半自動化の入口にあたる。
この方法は実運用にも耐える。筆者がこのワークフローで生成した素材は、実際にストックフォトの審査を通過する品質で運用できた。理屈だけの手順ではなく、商用の審査基準を満たす出力をまとめて作るために使ってきた仕組みである。
辞書式自動化とは|手作業とAPIの中間に置ける半自動化
ComfyUIの自動化は、突き詰めれば手作業とAPIの両端に整理できる。片方は、ノード上でプロンプトやseed・steps・cfg・画像サイズを毎回手で打ち替えるやり方。分かりやすいが、何十パターンも作るには向かない。もう片方は、PythonやAPIでワークフローを外部から叩くやり方で、自由度は高いが非エンジニアには導入のハードルが高い。
辞書式自動化は、その中間に位置する。プロンプトや生成パラメータを「キーと値」のセットとして1行にまとめ、ComfyUI側でその1行を辞書として読み込み、必要な値だけを各ノードへ分配する。画面のプロンプト欄に直接打ち込む代わりに、外部テキストに書いた1行を、ComfyUIの中で読み取って使うわけだ。コードは書かないが、1行を差し替えるだけで生成条件がまるごと切り替わる。ComfyUI自体の前提や必要スペックはComfyUIとは(必要スペックと始め方)に整理がある。
手作業との違いは、繰り返しの場面で効いてくる。1枚ごとにノードを開いてプロンプトを書き換え、seedを変え、サイズを直し、出力名を付け直す。この一連を10枚、100枚と続けるのは骨が折れる。辞書式自動化では、その繰り返しを外部テキストの行に逃がす。ノード側は「1行を受け取って分配する」形を一度組めば固定で、変えるのはテキストの中身だけになる。条件を一覧で見渡せるので、どの1本をどう変えたかも追いやすい。手で打ち替える回数が減るため、打ち間違いによる作り直しも起きにくくなる。
辞書式自動化でできること
辞書式自動化で扱えるのは、プロンプトの外部管理だけではない。negative prompt、seed、steps、cfg、画像サイズ、出力ファイル名まで、1本ごとに変えられる。手元のプロンプトをメモ帳ベースでまとめ、複数本の指示としてComfyUIへ流し込める。毎回ノードを手で操作するやり方に比べ、生成条件を見渡しやすく、後から差し替えやすい。たとえば商用素材を量産する場面では、指示書を番号付きで並べておけば、同じ品質基準のバリエーションを一気に作れる。VRAMに余裕のある環境で本数を稼ぐなら、ComfyUIのマルチGPU運用や、動画素材まで含めた16GBでの量産の実測も合わせて参考になる。
橋渡しに使うComfyUIノードと処理の流れ
外部テキストの1行をComfyUIの各ノードへ橋渡しする流れは、読み込み・辞書化・取り出し・型変換・分配の順で組み立てる。筆者のワークフローで使っていたのは次のノードで、いずれもWAS Node SuiteとComfyrollに含まれる、追加インストールで使える標準的なノードだ。
| ノード | 役割 |
|---|---|
| Text Load Line From File | 外部テキストから指定した1行(=1本分の指示)を読み込む |
| Text Dictionary Convert | 読み込んだ1行のJSONを辞書として解釈する |
| Text Dictionary Get | 辞書から必要なキーの値だけを取り出す(キーごとに1つずつ) |
| CR String To Number | 文字列で取り出したsteps・cfg・seed・width・heightを数値に変換する |
| CR Text | プロンプト文やファイル名など、変換せず受け渡すテキストを扱う |
| CLIP Text Encode | 取り出したpositive/negativeを通常どおりCLIPへ渡す |
| Empty Latent Image | width/heightを受け取り画像サイズを決める |
| KSampler | seed・steps・cfgを受けて画像を生成する |
仕組みができてしまえば、ComfyUIのノードを毎回いじらなくても、外部テキストの中身を書き換えるだけで生成条件が変わる。辞書式自動化とは、ComfyUIの外にある1行の生成指示を、ComfyUI内の各ノードへ橋渡しする方法だと言える。
まずはプロンプトの2つだけで動かす
いきなり全項目を詰め込む必要はない。まずは簡単な構成として、外部テキストから渡すのをポジティブプロンプトとネガティブプロンプトの2つだけにしてみる。実際にノードで組むと、次のような最小構成になる。
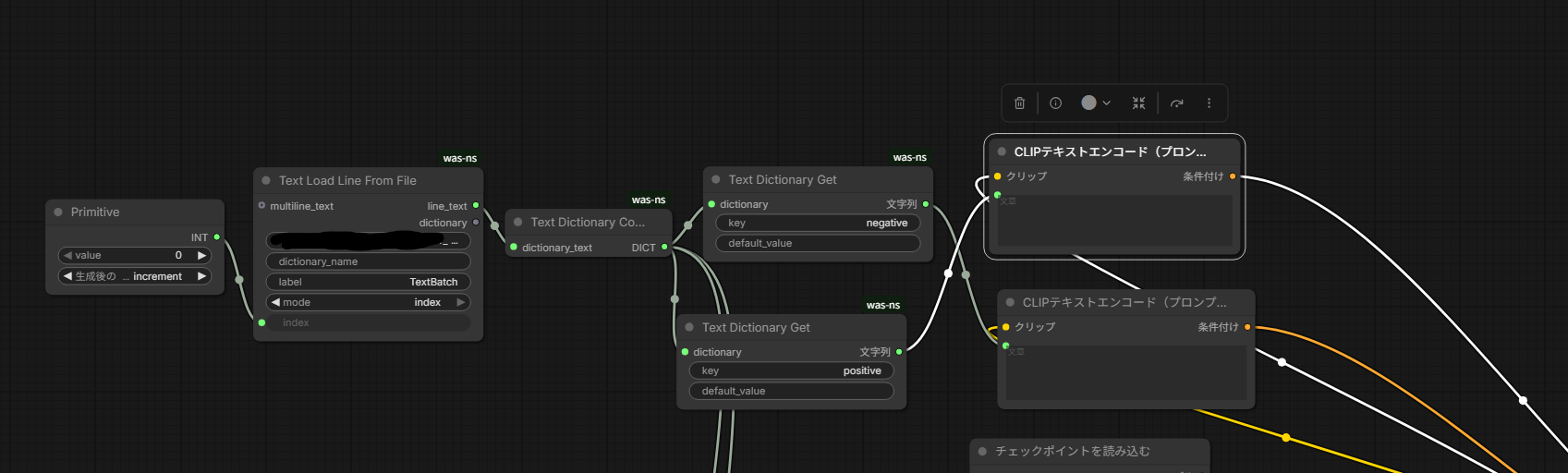
図のノードを左から順に見ていく。
- Primitive(INT):読み込む行番号(index)を持つノード。ここが辞書式自動化のいちばんの肝になる。値を0にして「生成後の制御」をincrement(増加)にしておくと、生成のたびに番号が自動で1つ進む。0で実行すると最初の行が読み込まれ、番号は1へ。もう一度実行すると2行目、その次は3行目というように、実行するたびに1つ下の行へ移る。10回実行すれば番号は0→1→2…と進み、1〜10行目が1回ずつ順に読まれる。手で行を選び直さなくても、回した回数だけ次の指示へ進んでいく仕掛けだ。
- Text Load Line From File:テキストファイルのパスと行番号を受け取り、その行を読み込む。この読み込み先のテキストファイルに、1行=1本のメモ形式(このあと示す1行JSON。項目を増やした完全な形は後述する)を、行ごとに並べておく。modeをindexにすると、Primitiveが指す番号の行を読み、その1行を次へ渡す。
- Text Dictionary Convert:読み込んだ1行のJSONを、辞書(DICT)に変換する。
- Text Dictionary Get(2つ):1行のテキストを項目ごとに振り分ける、フィルタの層にあたる。辞書から、keyで指定した値だけを取り出すノードで、後述のフォーマットどおりに各値を並べておけば、ここで1行が
positiveやnegativeといった部品に分割される。最小構成では、片方のkeyにpositive、もう片方にnegativeを入れ、それぞれの文字列を得る。値が見つからないとき用のdefault_valueも指定できる。 - CLIPテキストエンコード(2つ):取り出したpositive・negativeを、それぞれCLIPへ渡す。プロンプト欄に手入力する代わりに、辞書から取った値をここへ流し込む形になる。
この最小構成のポイントは、Primitiveのincrementで行番号が自動で進むところだ。1回生成するごとに次の行へ移るので、ノードを触らずに、テキストに並べた行を順番に消化できる。プロンプト欄に手で打ち込む代わりに、外部テキストの1行が読み込まれて内容が切り替わる。seedやサイズを毎回変えないなら、まずはこの形で十分に回る。プロンプトだけを大量に試したいときに、いちばん手数の少ない入口になる。慣れるまでは、この2キーの構成で「外部テキストを差し替えると生成が変わる」感覚をつかんでおくとよい。
そして、これらのノードが読み込むテキストの中身が、1行=1本の指示になる。最小構成では、ポジティブとネガティブの2キーだけを使う。書き方(フォーマット)はこうだ。
{"positive":"ここにポジティブプロンプト","negative":"ここにネガティブプロンプト"}positive にポジティブプロンプト、negative にネガティブプロンプトを入れる、2キーだけのJSON。値を囲む引用符(”)以外の記号は足さず、文字をそのまま入れるこのフォーマットに値を入れて実際に書くと、たとえば次の1行になる。これを1行ずつ並べれば、行の数だけ生成指示を用意できる。
{"positive":"a clean studio product shot, soft lighting, high detail","negative":"text, watermark, logo, blurry, low quality"}なお、キー名(positive や negative)そのものは、値を振り分けるための目印(トリガー)にすぎない。JSON側のキーと、Text Dictionary Get で指定する key がそろってさえいれば、名前は自分が認識しやすいものに変えてかまわない。大事なのは名前ではなく、1行を項目ごとにフィルタ分けして、各プロンプトやパラメータを正しいノードへ送り込むことだ。
応用編|つなげられる入力は、外から制御できる
最小構成で外部テキストから渡したのは、プロンプトの2つだけだった。だが辞書式の考え方そのものは、プロンプトに限らない。ComfyUIのノードで手入力している欄の多くは、線をつなげる「入力」として開ける。つなげられる欄は、辞書から取り出した値で外から動かせる。seedやsteps、cfg、画像サイズ、出力ファイル名はもちろん、その先のサンプラーやスケジューラ、さらに動画化やフレーム補間といった工程まで、同じやり方で1行のテキストから制御できる。
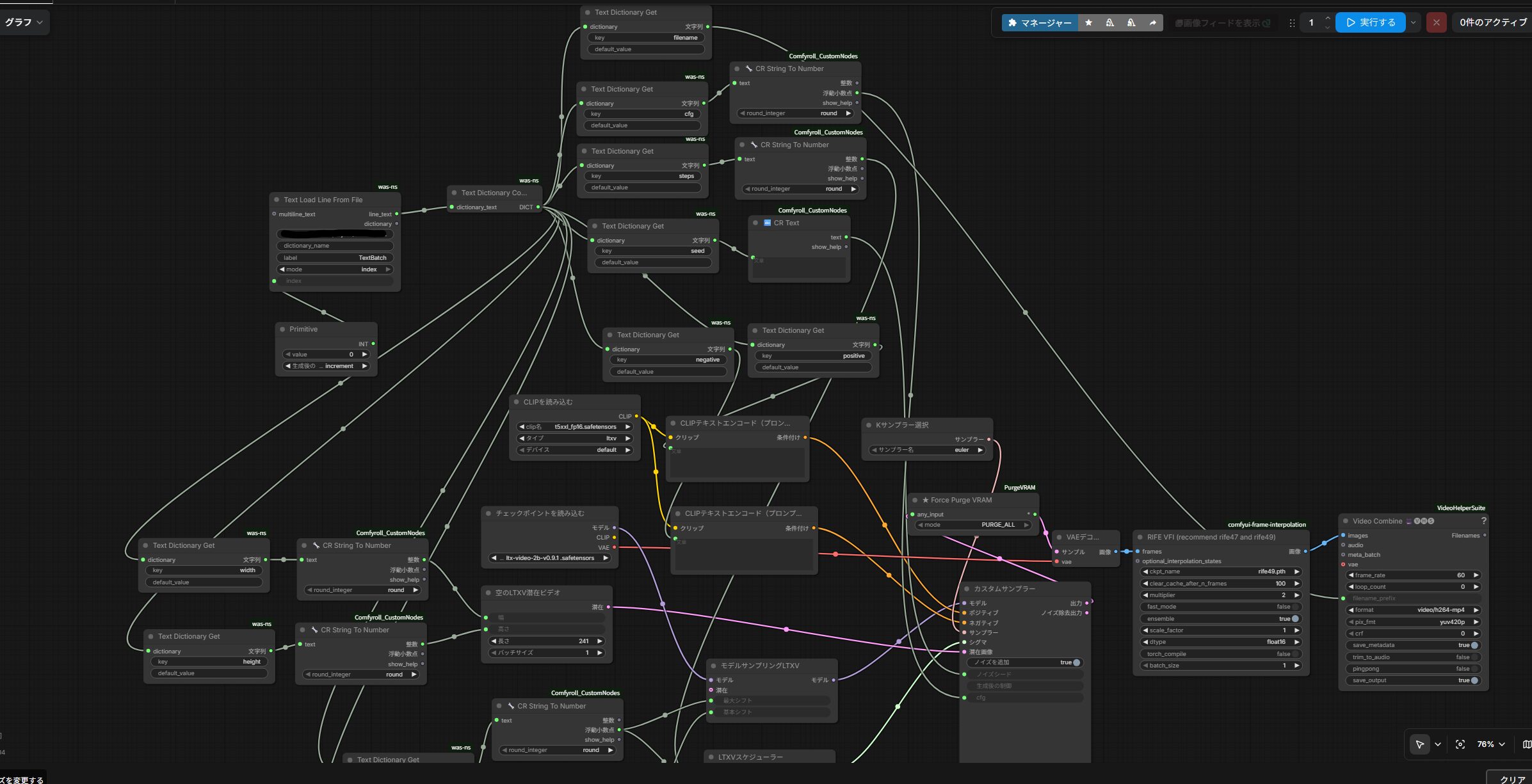
やっていることは最小構成と同じで、「手で値を入れている欄を、辞書から取り出した値に置き換える」だけだ。置き換える欄を増やすほど、外から制御できる範囲が広がる。最小構成にキーを足していけば、自然とこの応用編になる。
ひとつ注意点がある。外部テキストから取り出した値は文字列なので、数値として使う欄には CR String To Number で変換してから渡す。このとき、つなぎ先のノードが求める型に合わせて、整数(integer)と浮動小数点(float)を使い分ける必要がある。steps・seed・width・heightは整数、cfgのように小数を取る値は浮動小数点で渡す。ノードによっては、浮動小数点で入力しないとエラーを出すものがあるので、つなぐ前にその欄が整数か小数かを確かめておくとよい。CR String To Number は整数と浮動小数点の両方を出力するので、渡し先に合う方を選んでつなぐ。
制御する項目を増やす|seed・steps・サイズ・出力名
2キーで動くようになったら、外部テキスト側に渡す項目を少しずつ増やしていく。seedを1本ごとに変えたい、stepsやcfgを振りたい、画像サイズを切り替えたい、出力ファイル名を指定したい。こうした要望が出てきたら、その都度キーをJSONに足せばよい。最終的には、1行に次のような情報までまとめられる。
{"filename":"product_001","positive":"a clean studio product shot, soft lighting, high detail","negative":"text, watermark, logo, blurry, low quality","steps":30,"cfg":5.0,"seed":123456789,"width":1152,"height":640}| キー | 役割 | 渡し先 |
|---|---|---|
| filename | 出力ファイル名 | 保存ノード |
| positive / negative | ポジティブ/ネガティブプロンプト | CLIP Text Encode |
| steps / cfg / seed | サンプラーの生成パラメータ | KSampler |
| width / height | 画像サイズ(1本ごとに16:9・1:1・縦長などを切り替え) | Empty Latent Image |
数値として使う欄(steps・cfg・seed・width・height)は、前述のとおり CR String To Number で変換し、整数か浮動小数点かを渡し先に合わせてつなぐ。プロンプトやファイル名のように文字列のまま使うものは、CR Text 経由でそのまま渡せばよい。
実際に使っていた動画生成プロンプトの例
ちなみに、筆者は実際にこのような形で運用していた。下の2本は、LTX系の動画生成で実際に流していた外部テキストを載せている。ここで見てほしいのは、プロンプト本文の中身そのものではなく、positive・negative・seed・steps・cfg・解像度・出力名を、1本の生成ジョブとして同じ行にまとめている点だ。
{"filename": "R3_H_001_CLE_Static_88808", "positive": "(Architectural White Abstraction: High-Fiber Matte Paper and Silk:1.3), (Panoramic wide composition, subject centered, equal negative space on both sides:1.2), Wind-Driven Fabric Wave, Thread count density shadow gradient, seamless looping motion, first and last frame match, stable camera, temporal coherence, smooth continuous motion, Tripod shot, locked off camera, stable composition, no movement, perfect framing, Central composition, Clear spatial structure. The high-fiber matte paper folds downward slowly, creating creases that deepen over a few seconds, with shadow depth increasing in each fold before settling. As light hits the fabric surface, bright white background, overexposed bloom, sterile environment, shadowless, intense brightness, High-Key lighting, clean white background, clinical tone, low contrast, laboratory quality, neutral daylight color temperature, pure whites and silver highlights, Sharp Black outlines, high-fiber matte paper grain, anisotropic silk reflection, soft-body physics, bending stiffness, ultra-fine woven high density, satin weave, microfiber density, diffuse albedo map, roughness variation, tactile surface render, Minimalist precision, high-end studio aesthetic, medical and scientific clarity, trustworthy and serene visual tone. Cinematic 16:9, Widescreen, Anamorphic lens, anisotropic silk sheen direction-dependent, bending micro-crease, thread-count tactile detail, medium shot, product photography composition, clear focus, balanced framing, studio shot standard, Detailed, Vibrant, Digital, No People, Simulation, Paper, Cinematic, Cloth, Soft, Background, Fabric, Volumetric, Slow Living, Mindful Aesthetics, natural flow, gravity compliant, rhythmic cinematic timing, organic pacing, ultra high resolution, optimal depth of field, optical realism, pristine quality, sharp detail, (no text:1.2)", "negative": "(text:2.0), (watermark:2.0), (logo:2.0), (ui:2.0), (hud:2.0), (digits:2.0), (numbers:2.0), (bad geometry:1.5), (amorphous:1.5), (unstructured:1.5), (muddy:1.5), (blurry focus:1.3), (static:1.5), (frozen:1.5), (statue:1.5), (still image:1.5), (solidified:1.3), (motionless:1.5), (grid:1.5), (mesh:1.5), (dots:1.5), (pixelated:1.5), (pattern:1.5), (human:1.5), (face:1.5), (hand:1.5), (skin:1.5), (animal:1.5), (low resolution:1.3), (artifacts:1.3), (morphing:1.5), (shaking:1.5), (flickering:1.5), (glitch:1.2), (dirt:1.8), (messy:1.8), (dark:1.5), (grain:1.8), (shadow:1.3), (grungy:1.8), (stain:1.8), (rough:1.5), (Liquid:1.3), (Water:1.3), (Rigid:1.3), (Metal:1.3), (Rock:1.3), (Flesh:1.3), (Wet:1.3), (Glossy:1.3), (Reflective:1.3), (Chrome:1.3), (Neon:1.3), (Crumpled:1.3), (Torn:1.3), (Stained:1.3), (Dirty fabric:1.3), (noise:1.5)", "steps": 70, "cfg": 3.6, "seed": 830953665588808, "width": 1152, "height": 640, "max_shift": 1.8, "base_shift": 0.3}
{"filename": "R4_H_001_LUX_Static_50645", "positive": "(Optical Prism Geometry: Diamond Facet Light Dispersion:1.3), (Rule of thirds horizontal composition, subject at left intersection, open space right:1.2), (sharp defined structural edges:1.2), Caustic Rainbow Floor Projection, Critical angle total internal reflection, Chromatic dispersion wavelength separation, seamless looping motion, first and last frame match, stable camera, temporal coherence, smooth continuous motion, Tripod shot, locked off camera, stable composition, no movement, perfect framing, Central composition, Clear spatial structure. The diamond rotates slowly around its vertical axis, its active facets catching direct light one at a time. As it turns, hard directional spotlight, dramatic chiaroscuro, deep black shadows, high contrast, focused beam, Brilliant White Core, warm golden tones, rich cinematic contrast, premium atmospheric glow, expensive editorial look, sculpted soft shadows, luxurious amber grading, 24k gold tint, velvet dark mid-tones, elegant warm ambience, Black velvet background, spectral rainbow caustic, diamond brilliant-cut geometry, clear refractive index, fire dispersion B-G-V spectrum, brilliance scintillation, photon light simulation caustic, zero-roughness specular microfacet, physically rendered gem render, chromatic dispersion, hyper-sharp structural edges, defined crisp outlines, opulent and expensive visual language, gold and amber warmth, premium brand elegance. Cinematic 16:9, Widescreen, Anamorphic lens, medium shot, product photography composition, clear focus, balanced framing, studio shot standard, Caustics, Generative, Detailed, Texture, Vibrant, Background, No People, super slow motion, weightless drift, graceful deceleration, ultra high resolution, optimal depth of field, optical realism, pristine quality, sharp detail, (no text:1.2)", "negative": "(text:2.0), (watermark:2.0), (logo:2.0), (ui:2.0), (hud:2.0), (digits:2.0), (numbers:2.0), (bad geometry:1.5), (amorphous:1.5), (unstructured:1.5), (muddy:1.5), (blurry focus:1.3), (static:1.5), (frozen:1.5), (statue:1.5), (still image:1.5), (solidified:1.3), (motionless:1.5), (grid:1.5), (mesh:1.5), (dots:1.5), (pixelated:1.5), (pattern:1.5), (human:1.5), (face:1.5), (hand:1.5), (skin:1.5), (animal:1.5), (low resolution:1.3), (artifacts:1.3), (morphing:1.5), (shaking:1.5), (flickering:1.5), (glitch:1.2), (cheap:1.8), (plastic:1.5), (grain:1.8), (noise:1.8), (rough:1.5), (overexposed:1.3), (low quality:1.8), (Opaque:1.3), (Matte:1.3), (Metal:1.3), (Wood:1.3), (Organic:1.3), (Soft:1.3), (Liquid splash:1.3), (Dust:1.3), (Dirt:1.3), (Rock:1.3), (Sand:1.3), (Fabric:1.3), (Shattered:1.3), (Broken:1.3), (Cracked:1.3), (Debris:1.3), (Ice crystal:1.3), (Snowflake:1.3), (Frost:1.3)", "steps": 80, "cfg": 3.8, "seed": 407411198950645, "width": 1152, "height": 640, "max_shift": 1.95, "base_shift": 0.42}持っているプロンプトをチャットAIでフォーマットに整える
ここで一つ、はっきり分けておきたい。この記事で扱うのは、プロンプトそのものの書き方ではない。良いpositive/negativeをどう考えるかは別の話で、ここで扱うのはすでに手元にあるプロンプトとパラメータを、辞書式自動化が読めるフォーマットに整える工程だ。使いたいプロンプト、決めてあるsteps・cfg・seed・画像サイズ。こうした材料がそろっているとき、それを1行JSONの形に直す作業を、チャットAIに任せると速い。
フォーマットへの変換そのものは単純だが、手で何十本も書くと、引用符の閉じ忘れやカンマの位置といった崩れが混ざりやすい。ChatGPTやClaudeに「この内容を次のフォーマットの1行JSONにして」と渡せば、決まった形へ機械的に整えてくれる。複数本まとめて整形させれば、手作業より速く、形の崩れも起きにくい。ローカルのOllamaに整形を任せれば、クラウドに渡さず手元で完結させることもできる。
チャットAIに頼むときは、出力フォーマットを先に固定しておくとぶれない。たとえば次のように指示する。
これから渡す複数本のプロンプトとパラメータを、1本につき1行のJSONに整形してください。
キー:filename, positive, negative, steps, cfg, seed, width, height
・1本ごとに改行なしの1行JSONにし、渡した本数だけ行を並べる
・キーはこの順番でそろえ、過不足なく入れる
・渡した文面はそのまま該当キーに入れ、内容を作り変えない
・steps・cfg・seed・width・height は渡した数値をそのまま入れる
・説明文やコードブロックは付けず、JSONの行だけを返す
出力例(この形式・キー順のとおりに、1行ずつ返す):
{"filename":"product_001","positive":"a clean studio product shot, soft lighting, high detail","negative":"text, watermark, logo, blurry, low quality","steps":30,"cfg":5.0,"seed":123456789,"width":1152,"height":640}ここでフォーマットを厳密に指定するのには理由がある。辞書式自動化はJSONをそのまま機械的に読み込むので、形が少しでも崩れると(キー名の綴り違い、閉じ忘れの引用符、行末の余分なカンマ、説明文の混入)、Text Dictionary Convert が解釈に失敗し、ノード側がエラーを吐く。だからチャットAIへの指示では、「1行JSONで」「説明文やコードブロックは付けない」「キー名は固定」をはっきり伝える。出力をそのまま貼って動く状態にしておくことが、まとめて回すときのコツになる。最初は1行だけで試して、正しく分配されるかを確かめてから本数を増やすと安全だ。
テンプレートのキーは一例で、自分のノード構成に合わせて減らしてかまわない。filenameやサイズを使わないなら、そのキーは省けばよい。キー名は値を振り分けるための目印にすぎず、その文字がプロンプトに混ざることはないので、使わないキーが1行に残っていても、対応するノードを置いていなければ読み飛ばされるだけなので、気にする必要はない。
動画向けのプロンプト(先ほどのメモ例のように記述が長いもの)も、同じテンプレートでフォーマットに整えられる。ただし本数が多いときは、チャットモデルのコンテキスト(一度に扱える量)を意識しておくとよい。理屈のうえでは100本をまとめて整形させ、1つのテキストにまとめることもできるが、長いプロンプトの場合、10〜20本を超えたあたりから整形の精度が落ちる可能性がある。出力が長くなるほど、引用符の崩れや内容の取りこぼしが起きやすくなるためだ。その場合は、精度が保てる範囲の本数に分けて整形させ、テキストに少しずつ書き足していくと安定する。
流れにすると、自分でプロンプトとパラメータを用意する→チャットAIで指定フォーマットの1行JSONに整える→テキストファイルに貼る→ComfyUIが1行ずつ読み込む→1行ごとに条件を切り替えて生成する、という形になる。プロンプトを考える工程と、それをフォーマットへ整える工程、実際に描く工程を切り分けられるのが、この組み合わせの強みだ。整形をローカルのOllamaに任せる場合は、モデルや量子化で処理の速さが変わるため、ローカルLLMの量子化(Q4_K_M・Q8_0・FP16)の実測比較を目安にするとよい。
運用を回すためのコツ
辞書式自動化を実運用に乗せるなら、いくつか決めておくと楽になる。まずファイル名で、filenameに連番や区分を入れておくと(たとえばproduct_001、product_002)、どの出力がどの指示から生まれたかを後から追える。filenameに用途やテイストの区別も入れておけば、大量に作ったあとの仕分けや絞り込みがしやすくなる。1行が生成条件と出力名をまとめて持つので、テキストファイル1つが素材の台帳のようにも働く。メモ帳で保存するときは、文字コードをUTF-8にしておくと安全だ。日本語を含むファイル名やプロンプトを使う場合、Shift-JISなどのままだと読み込みで文字化けや解釈エラーが起きることがある。
うまくいかない1本が出たときの対処も軽い。該当する行だけを直し、その行をもう一度読み込ませればよい。ノードのつなぎ替えではなく、テキストの1行を直すだけで済むのが、毎回ノードを操作する手作業との大きな違いだ。ネガティブプロンプトを全本で共通化しておけば、品質の下限もそろえやすい。生成の途中でVRAMが足りずに止まる場合の切り分けは、VRAM不足エラーの原因と解決法が参考になる。
作った素材をアップスケールや動画まで通すなら、生成後の工程も外部処理にまとめておくと一貫する。ComfyUIの外でESRGANを動かすアップスケールのように生成と後処理を分けておけば、辞書式の「指示書ベースで回す」考え方を、そのまま後段にも広げられる。生成条件をテキストで管理するこの形は、連番で素材をそろえたい場面とは相性がよい。
向いている人・向かない場面
この方法が向くのは、ComfyUIのノードは触れるがPythonやAPIには進みにくい人、毎回ノードを手で変えるのが面倒な人、手元のプロンプトをまとめて使いたい人、画像や動画の素材を複数パターン作りたい人だ。本格的なAPI自動化に進む前の、軽い運用方法としても使える。
一方で、万能ではない。高度な分岐処理、大規模なエラー処理、外部データベースとの連携、複雑なキュー管理まで踏み込むなら、PythonやAPIを使った自動化のほうが向く。辞書式自動化は「API自動化の完全な代替」ではなく、APIに進む前の中間レイヤーと考えると位置づけがはっきりする。手作業のComfyUIよりは自動化されていて、API自動化よりは導入が軽い。その間を埋めるのが辞書式自動化だ。導入時のスペック感はComfyUI推奨スペック(VRAM 8GB・12GB・16GB)を目安にするとよい。
まとめ
ComfyUIの自動化は、必ずしもAPIやPythonから始めなくてよい。まずはポジティブとネガティブの2つだけを外部テキストに逃がし、慣れてからseedやサイズ、出力名へと制御する項目を広げていけば、非エンジニアでも無理なく半自動化に届く。プロンプトや生成パラメータを1行のJSONにまとめ、ComfyUI内で辞書として分解して各ノードへ配る。コードを書けなくても、メモ帳とチャットAI、そしてComfyUIのノードを組み合わせるだけで、1行=1本の生成指示としてワークフローを動かせる。実際にこの手法で生成した素材はストックフォトの審査を通る品質で運用できており、入口としても、ComfyUI内で完結する軽量な自動化としても、辞書式自動化は十分に実用的な選択肢になる。
今回は実例として動画向けのプロンプトを取り上げたが、辞書式自動化の考え方は動画に限らない。ComfyUIのノードとテキストや数値を組み合わせて扱う場面なら(画像生成でも、アップスケールでも、動画やフレーム補間でも)、つなげられる入力さえあれば、ほとんどのケースに対応できる。APIに進むかどうかは、その先で必要になってから決めればいい。
よくある質問
辞書式自動化にプログラミングの知識は必要か
不要である。Pythonを書いたり、APIを叩いたり、workflow JSONを直接編集したりはしない。決めたフォーマットに沿って、メモ帳などのテキストに1行ずつ生成条件を書き、ComfyUI側で読み込むだけで動く。JSONの形式に値を当てはめる作業はあるが、コードを書く工程はない。
最初は何から手を付ければよいか
ポジティブとネガティブの2キーだけのJSONから始めるのがよい。seedやsteps、画像サイズはComfyUIのノード側の値をそのまま使い、外部テキストからはプロンプトの2つだけを渡す。これで「テキストの1行を差し替えると生成が変わる」流れを確かめてから、seedやサイズなど制御したい項目を1つずつ足していくと、つまずきにくい。
読み込みでエラーが出るときは何を見ればよいか
多くは1行JSONの形が崩れている。引用符の閉じ忘れ、キー名の綴り違い、行末の余分なカンマ、全角文字の混入、ファイルの文字コードがUTF-8でない(メモ帳のShift-JIS保存など)といったことがあると、Text Dictionary Convertが辞書に変換できずに止まる。まずは1行だけのファイルで試し、その1行が正しいJSONになっているかを確認する。チャットAIに整形させた場合は、説明文やコードブロックの記号が混ざっていないかも見るとよい。数値として使う項目をCR String To Numberで変換し忘れている場合も、KSamplerなどでエラーになる。
プロンプトもチャットAIに作ってもらえるか
この記事で扱うのは、プロンプトを作る工程ではなく、手元のプロンプトとパラメータをフォーマットへ整える工程だ。チャットAIには、用意した内容を指定フォーマットの1行JSONへ整形してもらう。プロンプトの中身をどう作るかは別の話なので、ここでは踏み込まない。整えた出力をテキストファイルに保存し、ComfyUIで1行ずつ読み込めば、そのまま生成に使える。フォーマットを崩さないよう、出力形式を指示で固定しておくのが安定運用のコツだ。
一度にどれくらいの本数を回せるか
テキストの行数だけ指示を並べられるので、本数そのものに上限はない。実際に何本を連続で回せるかは、解像度とGPUのVRAM、1本あたりの生成時間で決まる。1024px前後の画像なら、VRAM 16GB級のGPUで数十本から数百本をまとめて流すといった使い方になる。筆者の場合は、100本単位でテキストにまとめ、一度に流す運用をしていた。本数を増やすほど総時間は伸びるので、1本あたりの時間から所要時間を見積もっておくと、夜間にまとめて回すといった計画も立てやすい。
既存のワークフローに後から組み込めるか
組み込める。今あるワークフローのうち、プロンプトやseed、画像サイズを手入力していた箇所を、Text Dictionary Getから取り出した値に差し替えるだけでよい。生成の中心になるCLIP Text EncodeやKSampler、Empty Latent Imageはそのまま使い、入力の入り口だけを外部テキスト経由に変える形になる。最初から組み直す必要はなく、まずプロンプトとseedだけ外部化して動きを確かめ、慣れてから残りを移すと安全だ。

