
Black Forest Labsが公開したFLUX.2 Kleinは、画像生成モデルFLUX.2を軽量化した蒸留版で、9Bと4Bの2サイズがある。このうち9B版について、配布元のHugging Faceモデルカードでは、fp8形式でおよそ29GBのVRAMとRTX 4090以上が目安として案内されている。BFL公式サイトのモデル一覧では蒸留9Bの目安を19.6GBとしており、表示箇所や実行条件によって前提は異なるが、いずれの数字でも手元のVRAM 16GBのカードには届かない。だが量子化と実行時のオフロードを組み合わせれば、この壁は実際には越えられる。
このモデルは、ブラウザですぐ試せるオンライン生成サービスや無料のデモも出回っていて、GPUを持っていなくても手軽に触れる。ただ、生成枚数やコストの上限を気にせず使いたい、画像や入力を手元の外に出したくない、アップスケールや量産まで自分の作業手順に組み込みたいとなると、自分のPCで動かす選択肢が現実味を帯びる。そこで問題になるのがVRAMだ。
本記事では、FLUX.2 Klein 9Bの蒸留版をQ8_0のGGUF量子化に置き換え、ComfyUI上でRTX 5080とRTX 5060 Tiという、いずれもVRAM 16GBの2枚で動かした実測を扱う。1024×1024・4ステップの生成は、RTX 5080で1枚あたり約8秒、RTX 5060 Tiで約14.5秒。出力は同じモデル・同じ設定を使うため画質傾向は基本的に同等で、差は主に生成時間とVRAM余白に表れた。ただしVRAMのピークは総量で14GB前後に達し、16GBに対する余白は薄い。生成のボトルネックはカードによって表れ方が異なり、速いRTX 5080ではテキストエンコードやオフロード転送の待ち時間が、RTX 5060 Tiでは演算性能の差がより前に出たと見られる。計測は速度・VRAM・消費電力・GPU使用率・温度を200ミリ秒間隔で記録し、seedや設定値も含めて再現できる形で残している。
FLUX.2 Klein 9Bとは何か
FLUX.2 Klein 9Bは、9Bパラメータの整流フロー型トランスフォーマに、テキスト側として8BのQwen3を組み合わせた構成で、推論を4ステップまで蒸留したモデルである。FLUX.1がT5系のテキストエンコーダを用いていたのに対し、FLUX.2 KleinはQwen3を採用しており、VAEも専用のものに変わっている。同じKleinでも、20ステップ・ガイダンス5前後で動かすbase版と、4ステップ・ガイダンス1で動く蒸留版の2系統が用意されている。本記事が測ったのは後者の蒸留版で、少ないステップで速く描ける半面、テキスト描画のような細部では当たり外れが出る。
ライセンスはサイズで分かれている。9B版はFLUX Non-Commercial License(非商用ライセンス)で、モデルそのものを商用目的で使うこと——有償サービスへの組み込みや商用での再配布など——は許可されていない。一方で4B版はApache 2.0で、モデルごと商用利用が認められている。ここで実務上重要なのは出力物の扱いで、非商用ライセンスの条文では生成された画像(Outputs)について「商用を含むいかなる目的にも使用してよい」と明記されている。つまり9B版でも、生成した画像自体は商用に使える(競合モデルの学習に使うといった用途は除く)。モデルを事業に組み込みたいのか、生成した画像を使いたいだけなのかで、見るべき条項が変わる。ライセンスは改定されることがあるため、利用前に配布元の最新の条文を確認するのが前提になる(本記事は2026年6月時点)。
16GBに収めるための構成
Hugging Faceモデルカードの約29GBという値は、重みファイル単体のサイズではなく、テキストエンコーダ・VAE・実行時バッファ・オフロードの有無などを含む、実行時VRAMの目安と考えられる。これを16GBに収めるには、モデル側を小さくし、同時に載せる量を減らす二方向の工夫がいる。具体的には次の構成をとった。
| 役割 | ファイル | サイズ | 配置先 | 入手元 |
|---|---|---|---|---|
| 拡散モデル(蒸留) | flux-2-klein-9b-Q8_0.gguf | 9.98GB | models/unet/ | unsloth(GGUF量子化) |
| テキストエンコーダ | qwen_3_8b_fp8mixed.safetensors | 8.66GB | models/text_encoders/ | Comfy-Org |
| VAE | flux2-vae.safetensors | 0.34GB | models/vae/ | Comfy-Org |
拡散モデルはfp8のsafetensors(約9.4GB)ではなく、Q8_0のGGUF量子化(9.98GB)を選んだ。GGUFはComfyUIのUnetLoaderGGUFノードで読み込む形式で、ローカルでの動画生成や大型モデルの低VRAM運用で広く使われている。GGUF版はこのUnetLoaderGGUF用としてmodels/unet/に置き、公式のfp8版を使う場合はComfyUI標準のmodels/diffusion_models/に置く点が異なる。量子化の形式ごとの容量と速度の関係はローカルLLMの量子化Q4_K_M・Q8_0・FP16の実測比較で扱ったとおりで、Q8_0はfp16に近い品質を保ちつつ容量を抑えられる位置にある。テキストエンコーダはfp8mixed版(8.66GB)を用い、VAEはFLUX.2専用のflux2-vae.safetensorsを使う。FLUX.1系のVAEを流用すると色が崩れる場合があるため、再現性を重視するなら専用品を使うのが安全である。
この構成でも、拡散モデルの9.98GBとエンコーダの8.66GBを単純に足せば18GBを超え、16GBには収まらない。実際に16GBで動くのは、ComfyUIがテキストエンコードと拡散の処理を時間的にずらし、エンコーダを使い終えたらVRAMから退避させて拡散モデルを載せる、逐次的なオフロードを行うためである。ComfyUI自体の必要スペックや前提はComfyUIとは(必要スペックと始め方)に整理がある。
ワークフローと再現手順
計測に使ったワークフローは、ComfyUIに標準で含まれるFLUX.2 Kleinのテキスト生成テンプレートを土台にし、拡散モデルの読み込みだけGGUF用に差し替えたものである。ノードの並びと設定値は次のとおりで、蒸留版の標準的な設定をそのまま用いている。
| 項目 | 設定値 |
|---|---|
| 拡散モデル読み込み | UnetLoaderGGUF(flux-2-klein-9b-Q8_0.gguf) |
| テキストエンコーダ | CLIPLoader(type: flux2 / qwen_3_8b_fp8mixed) |
| サンプラー | KSamplerSelect(euler)+ SamplerCustomAdvanced |
| スケジューラ | Flux2Scheduler(steps: 4) |
| ガイダンス | CFGGuider(cfg: 1.0)+ ConditioningZeroOut(ネガティブ無効化) |
| 潜在空間 | EmptyFlux2LatentImage(1024×1024 / batch 1) |
| 解像度 | 1024×1024 |
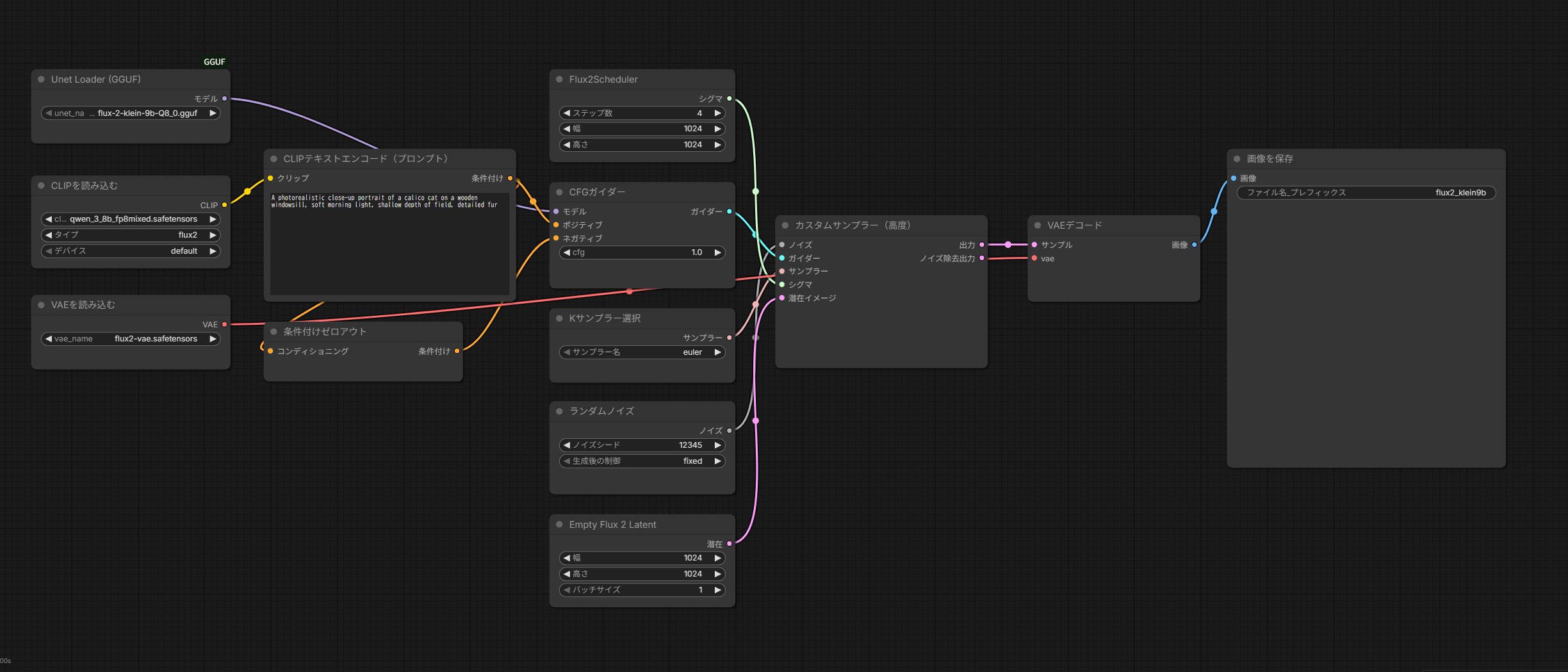
各画像のseedは、後述の4枚についてそれぞれ12345・222・333・444を用いた。実行環境はComfyUI v0.25.1、GGUF読み込みはComfyUI-GGUF 1.1.10、GPUはRTX 5080(VRAM 16GB、デバイス0)で、ComfyUIは標準のVRAM管理に任せ、precision系のフラグは付けていない。ベンチマークの数値は実行時のソフトウェアのバージョンで前後しうるため、これらのバージョンとともに記録している(計測日2026年6月20日)。FLUX.2 Kleinのテンプレートやノードは古いComfyUIでは見つからない場合があるため、公式ドキュメントの案内どおり、事前に最新版へ、必要に応じてNightly版へ更新しておくのが安全である。
実測 — 速度・VRAM・消費電力・使用率
まずRTX 5080(VRAM 16GB)で、アイドル状態を基準に、初回(モデル読み込みを含む)と定常(モデル読み込み後)を分けて計測した。VRAMはGPUボード全体の使用量で、Windowsのデスクトップ描画が常時消費する分(アイドル時2453MiB=約2.5GB)を含む。「VRAM増分」はそこからの上積み、つまりFLUX.2 Klein一式が占める実質的な量にあたる。
| 区分 | 生成時間 | GPU使用率 最大/平均 | VRAM最大 | VRAM増分 | 消費電力 最大/平均 | 温度 |
|---|---|---|---|---|---|---|
| アイドル基準 | — | 11% | 2453 MiB | — | 57.5 W | — |
| 初回(読み込み含む) | 11.35 s | 99% / 45% | 13328 MiB | 10875 MiB | 291.9 / 147.0 W | 67°C |
| 定常 1 | 8.31 s | 99% / 64% | 14392 MiB | 11939 MiB | 294.6 / 177.3 W | 67°C |
| 定常 2 | 8.29 s | 99% / 66% | 14296 MiB | 11843 MiB | 293.4 / 179.9 W | 65°C |
| 定常 3 | 8.23 s | 99% / 67% | 14008 MiB | 11555 MiB | 291.9 / 180.0 W | 65°C |
目につくのは、VRAMが16GBの上限に近いことだ。定常時の総使用量はピークで約14.4GB、モデル一式の増分は約11.9GBに達した。16GBに対する余白はおよそ1.9GiB(十進では約2GB弱)で、デスクトップの常時消費を差し引いた実効容量で見れば、1024×1024がほぼ上限に近い。解像度を上げれば潜在空間が大きくなり、この余白は急速に縮む(より高い解像度は本記事では計測していない)。VRAMが足りないときに何が起きるかはVRAM不足エラーの原因と解決法で扱っている。
速度の面で見えてくるのは、GPUの演算だけが生成時間を決めているわけではないことだ。生成中の使用率は瞬間最大こそ99%まで上がるが、定常の平均は65%前後にとどまった。4ステップの拡散そのものはGPUを振り切る一方、生成時間の一部はGPU演算ではなく、8BのQwen3によるテキストエンコード、エンコーダと拡散モデルの入れ替え、転送や同期の処理に使われていると考えられる。VRAMに余裕があり両方を常駐できる環境なら、この待ち時間は減り、より速くなる余地がある。16GBで動かす際の速度は、量子化の重さだけでなくオフロードの設計にも左右されやすい。
電力と発熱には余裕がある。消費電力のピークは約294Wで、RTX 5080の標準的なTGPである360Wに対して8割程度にとどまった。温度も65〜67°Cで、サーマルの制約には当たっていない。これは、GPUが演算を待つ時間がある分、電力も使い切らない、先に見た使用率の裏返しでもある。RTX 5080とVRAM 16GBの組み合わせで何が動き何が動かないかはRTX 5080 16GB VRAMの壁に関するよくある疑問にまとめている。
生成時間について補足すると、定常で約8.2〜8.3秒というのは、ソフトウェアとディスクキャッシュが温まった状態での値である。別の粗い計測ではモデルの常駐状態によって1枚あたり約10秒まで延びる場面もあった。テキストエンコーダがVRAMに残るかディスクから読み直すかで前後するため、実運用では1枚あたり8〜10秒程度を見込むのが妥当だろう。なお同じseedでも、GGUFの逐次オフロード経路では数値計算が完全には決定的にならず、再生成で細部が変わることがある。
RTX 5060 Tiとの比較 — 同じ16GBで違いは何か
VRAM 16GBはRTX 5080だけでなく、より手頃なRTX 5060 Tiにもある。同じ構成・同じseedで、RTX 5060 Tiでも測った。こちらはOculink接続のeGPUドックに載せたカードで、ディスプレイは接続していない。つまりデスクトップ描画の常時消費がなく、アイドル時のVRAMはわずか114MiBだった。
| 指標(1024×1024・4ステップ) | RTX 5080 | RTX 5060 Ti |
|---|---|---|
| 生成時間(定常) | 約8.3 秒 | 約14.5 秒 |
| 初回(読み込み含む) | 11.35 秒 | 16.88 秒 |
| GPU使用率 平均(定常) | 65% | 81% |
| VRAM増分(モデル一式) | 約11.9 GB | 約12.5 GB |
| VRAM総ピーク | 約14.4 GB | 約12.6 GB |
| アイドルVRAM | 2453 MiB(デスクトップ) | 114 MiB(表示なし) |
| 余白(対16GB) | 約1.9 GB | 約3.7 GB |
| 消費電力 平均/最大 | 約179 / 294 W | 約101 / 147 W |
| 1枚あたり電力量(概算) | 約1486 J | 約1465 J |
| 接続 | メインPCIeスロット | Oculink(eGPU) |
速度はRTX 5080が約1.75倍速い。ここまでは順当だが、GPU使用率は逆にRTX 5060 Tiの方が高い(平均81%対65%)点が目を引く。RTX 5080は演算が速く終わるため、テキストエンコードやオフロードで演算を待つ時間が相対的に長く、使用率の平均が下がる。一方RTX 5060 Tiは演算そのものが遅いため、待ち時間の比率が小さくなり、使用率が上がる。言い換えると、RTX 5080ではGPU演算以外の待ち時間(テキストエンコードやオフロード転送・同期)が相対的に大きく見え、RTX 5060 Tiでは使用率が高く演算性能の差がより表に出たと考えられる。ただしRTX 5060 TiはOculink接続のeGPU構成で、転送帯域やCPU側・同期の影響も混ざるため、厳密なカード単体の比較ではない。今回のログ上は生成時間の差に演算性能差が強く反映されているように見えるが、転送時間を分離して切り分けたものではない。
VRAMの使い方にも差が出た。RTX 5060 Tiはディスプレイを繋いでいないため、デスクトップ描画の約2.5GBがそのまま空く。総ピークは約12.6GBにとどまり、16GBに対する余白は約3.7GBと、RTX 5080の約1.9GBより厚い。同じ16GBでも、表示出力を担っていない専用カードの方が実効容量は大きい。これはカードの優劣ではなく構成の違いで、メインのGPUに画面を任せ、生成は別のカードに分けられる環境なら、16GBをより使い切れる。複数GPUを束ねる場合の挙動はデュアルGPUでローカルLLMを動かす実測でも扱っている。
消費電力は、1枚あたりに直すと拮抗する。平均電力と生成時間から概算すると、RTX 5080が約1486J、RTX 5060 Tiが約1465Jで、ほぼ同じだった。RTX 5080は速いが電力が高く、RTX 5060 Tiは遅いが電力が低い。電力のピークはRTX 5080が294W(標準TGP 360Wの約82%)、RTX 5060 Tiが147W(同180Wの約82%)で、どちらもTGPの8割前後で頭打ちになる。速度を最優先するならRTX 5080、コストや消費電力、VRAMの余白を重く見るならRTX 5060 Tiという選び分けになり、どちらの16GBでもFLUX.2 Klein 9Bは実用的に動く。
出力画像 — 4ステップ蒸留の実力と限界
計測と同じ条件で生成した4枚を、seedとともに示す。いずれも1024×1024・4ステップで、上の定常区間の計測に対応する。




写真風の被写体、製品、風景といった題材では、4ステップでも実用品質に届く。プロンプトへの追従も強い。弱点は文字で、看板やメニューのような描画は崩れやすく、回数を重ねないと意図どおりにならない。速く描けることと細部の安定は別の軸であり、4ステップ蒸留版は前者に振った設計だと捉えるのが実態に近い。なお品質の評価はここでは目視による主観であり、計測した速度やVRAMのように数値で確かめたものではない。
16GBで運用する際の注意点
16GBでFLUX.2 Klein 9Bを使うなら、いくつか押さえておく点がある。まず解像度は1024×1024を基本に考えるのが無難で、これを超えると潜在空間の拡大でVRAMの余白を食いつぶしやすい。次に、もし余白をさらに確保したいなら、より軽い量子化に落とす手がある。GGUFにはQ8_0(9.98GB)のほかQ6_K(7.87GB)やQ4_K_M(5.91GB)が用意されており、容量を削ればVRAMにゆとりが生まれる。品質との引き換えになるため、Q8_0で余白が薄いと感じた場合の選択肢として持っておくとよい。
速度を詰めたい場合は、テキストエンコーダの扱いが鍵になる。前述のとおり、待ち時間にはオフロードの転送が効いていると見られるため、エンコーダを常駐させられるだけのVRAMがあれば縮む余地がある。16GB単体ではここが難しく、2枚目のGPUにエンコーダを逃がす構成が効く場面もある。複数GPUでComfyUIを動かす際の挙動はComfyUIマルチGPU運用ガイドで実測している。動画生成まで含めて16GBで何ができるかはLTXを16GB VRAMで動かす実測も合わせて参考になる。
用途別にVRAM容量をどう見積もるかはComfyUI推奨スペック(VRAM 8GB・12GB・16GB)に、精度(fp16/bf16)の選び方はComfyUI FP16/BF16精度ガイドに詳しい。本記事のFLUX.2 Klein 9Bは、これらの延長線上で「16GBの上限ぎりぎりに大きめの生成モデルを載せる」一例にあたる。
まとめ
FLUX.2 Klein 9Bは、配布元のHugging Faceモデルカードが約29GB・RTX 4090以上を目安に挙げる(BFL公式サイトの一覧では蒸留9Bを19.6GBと表示)モデルだが、Q8_0のGGUF量子化とComfyUIの逐次オフロードを使えば、VRAM 16GBのカードでも1024×1024・4ステップを実用品質で生成できた。RTX 5080なら1枚あたり約8秒、RTX 5060 Tiなら約14.5秒で、速度差は約1.75倍。これらの目安は絶対の壁ではない。ただしVRAMのピークは14GB前後と上限に近く、解像度を上げる余地は小さい。ボトルネックの表れ方はカードで異なり、速いRTX 5080ではテキストエンコードやオフロードの待ち時間が、RTX 5060 Tiでは演算性能の差がより前に出た。1枚あたりの消費電力量で見れば両者は拮抗し、速度を取るならRTX 5080、コストと省電力・VRAM余白を取るならRTX 5060 Tiという選び分けになる。ライセンスは9B版がモデル非商用(生成画像は商用可)、商用でモデルごと使うなら4B版のApache 2.0が選択肢になる。16GBで大きめの生成モデルをどこまで動かせるかを見極める材料として、本記事の数値とseed・設定値が再現の出発点になれば幸いである。
よくある質問
FLUX.2 Klein 9Bは本当にVRAM 16GBで動くのか
動く。Q8_0のGGUF量子化とComfyUIの逐次オフロードを使えば、RTX 5080 16GBで1024×1024・4ステップを生成でき、実測ではVRAMのピークが約14.4GB(モデル一式の増分で約11.9GB)だった。ただし16GBに対する余白は約1.9GiB(約2GB弱)と薄く、解像度を上げると足りなくなりやすい。
クラウド(オンライン)で使うのと、自分のPCで動かすのはどう違うか
ブラウザで使えるオンライン生成や無料デモは、GPUもセットアップも要らず数秒で試せる手軽さが利点で、まず触ってみる用途に向く。一方、生成枚数やコストの上限を気にせず使いたい、画像や入力を自分の環境の外に出したくない、アップスケールや大量生成まで手元の作業手順に組み込みたい、といった場合は自分のPCで動かす意味が出てくる。その条件がVRAMで、本記事のとおりVRAM 16GBのGPUがあれば、RTX 5080でもRTX 5060 Tiでも1024×1024の生成は実用的に回せる。
生成した画像を仕事で使ってよいのか
9B版のライセンス(FLUX Non-Commercial License)では、モデルそのものの商用利用は認められない一方、生成された画像は商用を含む目的に使ってよいと明記されている(競合モデルの学習への利用は除く)。モデルを有償サービスなどに組み込みたい場合は、Apache 2.0で配布される4B版か、配布元の商用ライセンスを検討することになる。ただし出力物の利用にも、違法・権利侵害コンテンツを防ぐためのフィルタまたはレビュー、法令上必要なAI生成表示などの条件が付くため、商用利用時は最新の条文と運用条件を確認するのが前提となる。
どの量子化(quant)を選べばよいか
16GBならQ8_0(9.98GB)が品質と容量のバランスがよく、本記事もこれで計測した。余白をさらに確保したい、より高い解像度を試したいといった場合は、Q6_K(7.87GB)やQ4_K_M(5.91GB)に落とす選択肢がある。容量を削るほど品質との引き換えになる。
4ステップなのに1枚8秒かかるのはなぜか
拡散の4ステップ自体は速いが、生成全体ではQwen3-8Bによるテキストエンコードと、エンコーダ・拡散モデルを入れ替えるオフロードの転送に時間がかかる。実測ではGPU使用率の平均が65%前後にとどまり、生成時間の一部はGPU演算ではなく、テキストエンコードやモデルの入れ替え・転送・同期に使われていると考えられる。VRAMに余裕がありエンコーダを常駐できる環境なら、この待ち時間は縮む。
RTX 5060 Tiでも動くのか。RTX 5080とどちらがよいか
動く。RTX 5060 Ti(16GB)でも同じ構成で生成でき、1024×1024・4ステップが1枚あたり約14.5秒だった(RTX 5080の約8.3秒に対して約1.75倍)。VRAMの余白はRTX 5060 Tiの方が厚く(ディスプレイ非接続なら約3.7GB対約1.9GB)、消費電力も低い。1枚あたりの電力量はほぼ同じため、速度を最優先するならRTX 5080、コストと省電力・VRAMの余白を重視するならRTX 5060 Tiという選び方になる。1024×1024を数枚生成する程度なら、14.5秒でも実用上は気にならない。ただしこの後にアップスケールや大量のバッチ生成を回す前提なら、1枚あたり約6秒の差が枚数分積み上がるため、速度を優先してRTX 5080を選ぶ判断も十分にありうる。

