
テキスト生成AIの速度は、長く「1トークンずつ書き出す」逐次方式に縛られてきました。DiffusionGemmaは、その前提をひっくり返し、文章をまとまり単位で並列に整える拡散方式の実験的なオープンモデルです。Google DeepMindがGemma 4とGemini Diffusionの研究を土台に公開し、NVIDIAがGeForce RTXやDGX Spark向けに最適化しました。「速い文章生成を、クラウドに頼らず手元のPCで」という方向に、新しい選択肢が一つ増えています。
・DiffusionGemmaは、最大256トークンのまとまり(canvas)を複数ステップで並列にデノイズして生成する拡散方式の言語モデル
・従来のLLM(自己回帰方式)が1トークンずつ出すのに対し、まとまりを少ない回数のパスで仕上げる
・基盤はGemma 4(26B-A4B=合計約25.2BのMoE、推論時に活性化するのは約3.8B)で、Apache 2.0のオープンウェイト
・速度は公称で最大4〜5倍。ただし公称値で、DiffusionGemma自体の速度は当サイトでは未計測
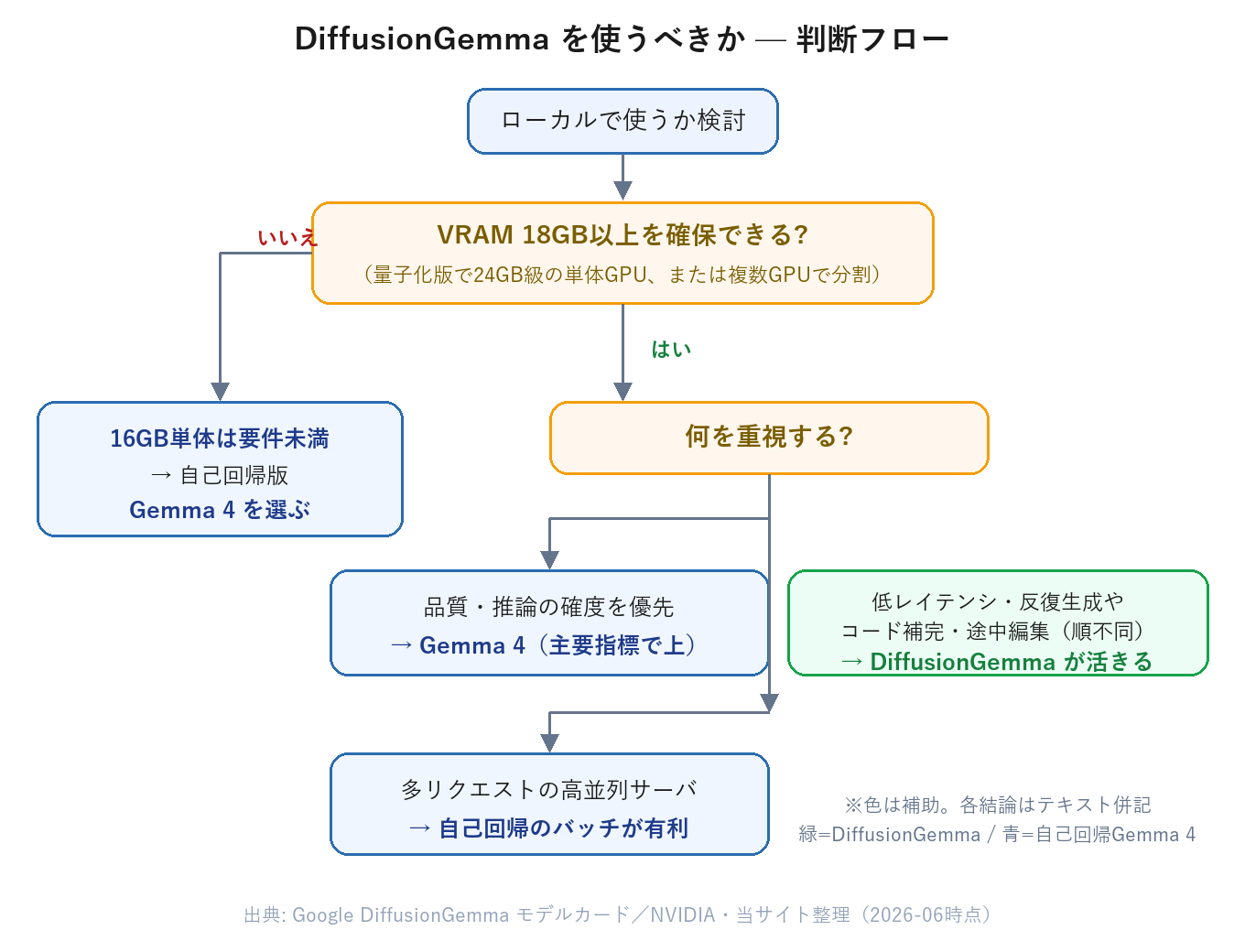
・品質は主要指標で同規模の自己回帰版Gemma 4に譲る。VRAMも量子化版で18〜24GB級(フル精度は60GB超)が要り、16GB単体では要件未満。用途で選ぶのが現実的
DiffusionGemmaとは|自己回帰方式との違いが出発点
DiffusionGemmaとは、ノイズから出発して文章のまとまり全体を並列に整えていく、拡散方式のテキスト生成モデルのことです。画像生成の拡散モデルと同じ発想を文章に持ち込み、Google DeepMindがGemma 4とGemini Diffusionの研究を組み合わせて公開しました。NVIDIA公式ブログとDeepMindのモデルページで、この設計が確認できます。
今広く使われている大規模言語モデル(LLM)の多くは「自己回帰」と呼ばれる方式で動いています。ここがDiffusionGemmaとの最大の分かれ目で、なぜ速いのかを理解する入口になります。
1トークンずつ出すか、まとまりで並列に出すか
自己回帰方式とは、直前までの単語を見て次の1トークン(単語や文字列片の単位)を決める、という逐次処理を繰り返す生成方法です。対話AIが文字を打ち込んでいくように見えるのは、この1トークンずつの出力が理由です。1語を生成しては次の計算を待つ、を延々と続けます。
DiffusionGemmaは別の道を選びました。最大256トークンのまとまり(canvas)を対象に、複数ステップかけて並列にデノイズ(ノイズ除去)して整えます。1語ずつ次を待つのではなく、まとまりを少ない回数のパスで仕上げていくのが速さの源です。順番に1語ずつ並べるのではなく、まとまりで考えるモデル、という整理ができます。
中身をもう少しかみ砕くと、最初はノイズに近いまとまりから出発し、何ステップかかけて全体を少しずつ鮮明な文章へ整えていきます。画像生成の拡散モデルが砂嵐から絵を浮かび上がらせるのと同じ発想です。DeepMindはこれを、次の1語を推測するのではなく段落全体を一度に扱う「非逐次(non-sequential)」な設計だと説明しています。なお公式モデルカードによれば、低バッチのH100・FP8で1回のパスあたり15〜20トークン相当の生成にあたり、256トークンが一度に確定するわけではなく、パスを重ねて仕上がっていきます。
速度については、Googleの発表では最大4倍、DeepMindのモデルページでは4〜5倍、NVIDIAの発表では同等の自己回帰モデル比でおおむね最大4倍と説明されています。いずれも公称値として受け取るのが妥当ですが、自己回帰の逐次処理という構造的なボトルネックを外しにいく狙いははっきりしています。
なぜローカルの「単一ユーザー処理」で効くのか
並列生成が最も効くのは、開発者や研究者が手元で1人だけモデルを動かす、単一ユーザーの処理です。クラウドの大規模サービスは、多数のリクエストをまとめて捌くことで効率を稼ぎます。ところが手元のPCで自分1人がモデルを叩く場面では、その「まとめ処理」の利点が出ません。
自己回帰方式だと、単一ユーザーの生成は1語ずつの待ち時間がそのまま体感速度に直結します。応答までの遅延(レイテンシ)が気になる用途ほど、この逐次処理が足を引っ張ります。DiffusionGemmaはまとまり単位で出すことで、まさにこの詰まりやすい領域に切り込みます。低バッチ・単一アクセラレータでの低レイテンシは、公式に想定された強みです。
| 観点 | 自己回帰方式(従来のLLM) | 拡散方式(DiffusionGemma) |
|---|---|---|
| 生成の単位 | 1トークンずつ逐次 | 最大256トークンのまとまりを複数ステップで並列デノイズ |
| 速度の決まり方 | 1語ごとに次の計算を待つ | まとまりを少ない回数のパスで仕上げる |
| 主なボトルネック | メモリ帯域(重みの読み出し) | 演算性能(行列計算・Tensor Core) |
| 得意な場面 | 高並列のサーバ処理(バッチで効率化) | 低バッチ・単一ユーザーの低レイテンシ(公称4〜5倍) |
| GPU選定で効く軸 | VRAM容量・帯域幅 | 演算性能 + VRAM容量(18〜24GB級) |
基盤はGemma 4の25.2B MoE|大きいのに動かすのは一部
DiffusionGemmaの基盤は、Gemma 4という合計約25.2BパラメータのMoEモデル(26B-A4Bと表記)に、拡散ヘッドを組み合わせた構成です。Gemmaが持つ言語理解の土台に、画像生成由来の拡散の出力方式を載せた、と見ると理解しやすくなります。ここで鍵になる「MoE」と「拡散ヘッド」を、順に噛み砕きます。
約25.2Bを積んで、動かすのは3.8B|MoEの効率化
MoE(Mixture of Experts=複数の専門家モデルを束ねる方式)とは、巨大なモデルのうち、その都度必要な一部だけを動かす設計です。DiffusionGemmaの基盤であるGemma 4は、合計約25.2B(26B-A4Bと表記される)パラメータを持ちながら、推論で実際に活性化するのは約3.8Bにとどまります。知識の引き出しは大きく保ちつつ、毎回の計算負荷は一部に絞れる、というのがMoEの利点です。
このMoEという考え方そのものは、自己回帰版のGemma 4でも共通です。当サイトでは自己回帰版のgemma4:26bを実測し、MoE構成で消費電力が大きく下がる挙動を別記事で扱っています。DiffusionGemmaは、このMoEの土台に、256トークンのまとまりをデノイズする拡散ヘッドを重ねた二段構えだ、と整理できます。
ここで誤解しやすいのが、MoEで節約できるのは「毎ステップの計算量」であって、VRAMに載せる重みの総量ではない、という点です。1ステップで動くのは3.8Bでも、全エキスパートはいつ呼ばれてもいいように、重み全体をメモリに載せておく必要があります。実際、自己回帰版のgemma4:26bは活性化が3.8Bでも、当サイトの実測でGPU使用量が15,612 MiB(約15.25 GiB)に達しました。つまりMoEは「演算は軽いがメモリは重い」構成で、GPU選びでは演算性能とVRAM容量の両方を見る必要があります。
Apache 2.0のオープンウェイトとローカル動作の意味
DiffusionGemmaは、重みが配布されるオープンウェイトのモデルで、Apache 2.0という寛容なライセンスで公開されています。重みが手に入るため、RTXやDGX Spark上で動かせます。公開初日から、推論基盤のvLLMやHugging Face Transformers、配布・ファインチューニング経路のUnslothなどが対応として挙げられており、普段からローカルLLMの推論エンジンを触っている人にはなじみのある顔ぶれです。クラウド契約もトークン単位の従量課金も不要だと、NVIDIAの発表に明示されています。なお、ライセンスは配布元ごとに確認するのが安全です。Googleが配布するDiffusionGemma本体はApache 2.0ですが、NVIDIAのNVFP4版など配布元が異なるチェックポイントは、その配布元モデルカードに記載された利用条件・禁止用途・追加条項を個別に確認してください。
もう一点、注意したいのは、「ローカルだから何も外に出ない」と無条件には言えない点です。モデル本体を手元で動かす限りは生成が手元で完結しますが、Web検索や外部APIとの連携を併用すればデータは外に出ます。外部送信を避けたいなら、ローカルモデル単体での運用に絞り、外部接続を無効化したうえで使う、という条件付きで考えるのが現実的です。
- 基盤アーキテクチャ
- Gemma 4(26B-A4B=合計約25.2BのMoE)+拡散ヘッド(Gemini Diffusion研究を反映)
- 推論時の活性化パラメータ
- 約3.8B
- 並列生成
- 最大256トークンのまとまり(canvas)を複数ステップでデノイズ(公式モデルカード: 低バッチH100・FP8で1パスあたり15〜20トークン相当)
- 入力 / 出力
- 入力: テキスト・画像(動画は画像フレーム列として処理する扱いで、公式カードは最大60秒・1fps想定)/ 出力: テキスト
- ライセンス
- Apache 2.0(オープンウェイト)。量子化再配布版は追加条件の確認を
- 対応実行基盤
- 推論: vLLM / Hugging Face Transformers / SGLang / MLX。量子化配布・ファインチューニング: Unsloth / NVIDIA NeMo(必要VRAMは配布形式で異なる)
- 動作環境
- 公式言及: GeForce RTX 4090/5090・RTX PRO・DGX Spark/Station・H100等。本記事はローカルのGeForce RTXを中心に扱う
- 位置づけ
- 実験的オープンモデル
速度をどう読むか|公称値と手元の実測の距離
本記事では、DiffusionGemma自体の独立実測は扱わず、公式の公称値と、当サイトの自己回帰版Gemma 4の実測を分けて参照します。公称値として示されているのは、単一のH100で1秒あたり1,000トークン超、DGX Sparkで毎秒150トークン前後、自己回帰の同等モデルと比べて最大4〜5倍、といった数字です。いずれもGoogle DeepMindとNVIDIAが公表した値で、当サイトで測ったものではありません。
一方、土台となる自己回帰版のGemma 4については、当サイトの定常ベンチで実測した参考値があります。条件は、RTX 5080単体・ドライバ610.47、モデルタグ gemma4:26b、生成512トークン(num_predict=512)を3回計測した平均です。サンプラーはベンチ共通の設定で、temperatureやseed、num_ctx、thinkingは個別に固定せずOllamaの既定で回しています。GPU上で実行されていること(CPUフォールバックでないこと)は、計測中のnvidia-smiログ(VRAM・消費電力・GPU温度)で確認しました(取得2026-06-12)。digestや各回の生ログは本記事には併載していないため、これらはあくまで当サイト環境での参考値として扱ってください。その条件で、gemma4:26bは3回平均で約36.4 tokens/sec、GPU総使用量は15,612 MiB(約15.25 GiB)でした。後者は実行中のGPU総使用量であってモデル重み単体のサイズではなく、いずれも自己回帰版の数字で、DiffusionGemma自体の速度・VRAMではありません。拡散方式が公称どおりの高速化を出すかどうかは、手元で動かせる環境が整い次第あらためて計測する領域です。
ここで分けておきたいのは、測った次元(自己回帰版の速度・VRAM)と、まだ測っていない次元(拡散版の実速度・体感品質)です。この二つを同じ強さで語ると、公称値が手元の再現値のように見えてしまいます。公称の4〜5倍は方向性を示す有力な数字ですが、手元で確かめた値として扱うのは現段階では避けます。
独立した実測が各所から出てくれば、この公称値が一般的なGPUでどこまで再現するかが見えてきます。現時点では、4〜5倍という幅をそのまま自分の環境の数字として当てにするのではなく、方式の方向性を示す指標として持っておくのが無難です。速度を語る材料が増えた段階で、この節は手元の実測を足して更新していく予定です。
ローカルGPU要件|帯域依存から演算依存への揺れ
拡散方式は、メモリ帯域よりも演算性能が効きやすい「計算集約型」の処理になりやすく、従来のローカルLLM選びの常識を少し揺らします。従来の自己回帰LLMは、1トークンごとに巨大な重みを読み出すため、メモリ帯域がボトルネックになりがちでした。だからローカルGPU選びでは「VRAM容量と帯域幅」が重視されてきました。拡散方式は、この前提が変わる可能性があります。
何がボトルネックになるか|演算量とTensor Core
まとまったトークンを並列にデノイズするとは、1パスあたりの行列計算がまとめて増える、ということです。逐次に重みを読み出して待つ自己回帰と違い、まとまった計算をGPUへ一気に投げる形になります。この性質上、少なくとも公式が示す低バッチのGPU推論という条件では、行列演算を高速化する専用ユニット(Tensor Core)の演算性能が効いてくる、と読み取れます。つまりボトルネックが「帯域待ち」から「演算量」へ移る可能性がある、という条件付きの観測です。あくまで公式が示す設計に基づく見立てで、手元での断定は計測が揃ってからにします。
VRAMはどれくらい要るか|16GB単体では足りない
DiffusionGemmaを動かすのに必要なVRAMは、実装と精度で大きく変わります。Googleの公式Transformers手順でBF16(フル精度)のチェックポイントをそのまま読む場合は、手順上60GB超のGPUが前提とされ、単体のコンシューマGPUの範囲を超えます。一方、量子化(Q4_K_M・Q8 など)すれば現実的なラインに下がり、Googleは量子化時に18GB VRAM枠へ収まる、あるいは24GBのRTX 5090/4090級に収まる、と説明しています。さらにコミュニティが配布するQ4_K_M量子化版では、ファイルサイズ約17GB・動作目安が約24GB VRAMとされています(Unslothの配布モデルカード、2026-06-12時点)。後者は非公式の配布物の目安で、公式要件ではありません。いずれにせよ、量子化版を実用的にGPUへ載せる前提でも18GB以上が目安で、16GB級GPU単体での全量GPU実行は本記事では要件未満として扱います(CPUオフロードや別量子化での起動可否・速度は未検証)。24GBクラスの単体GPUか、複数GPUに分割できる構成が現実的なラインです。
参考として、土台の自己回帰版gemma4:26bは当サイト実測でGPU総使用量15,612 MiB(約15.25 GiB)と16GBにほぼ収まりますが、これは拡散ヘッドや256トークンのまとまり分の作業領域(コンテキストやキャッシュのVRAM)を持たない自己回帰版の数字です。DiffusionGemma本体はこれより余裕が要ります。手元にあるRTX 5080やRTX 5060 Tiはいずれも16GBで(より軽いGemma 4 12Bなら16GBで実測できていますが)、単体ではDiffusionGemmaを余裕を持って動かすラインには届きません。ここで注意したいのは、16GBのGPUを2枚挿しても、VRAMが自動的に32GBの単一領域として使えるわけではない点です。複数GPUで動かせるかは、vLLMなどの実行基盤がDiffusionGemmaの分割ロードやテンソル並列に対応しているか次第で、本記事では未検証です。NVIDIAはGeForce RTXシリーズおよびDGX Sparkでの動作を公式にうたっていますが、実際のVRAM占有と速度は、手元で回せるようになった段階で実測する領域です。
実務的な読み方としては、二段階で見るのが安全です。第一に、VRAMに「収まるか」はこれまで通り最初の関門で、DiffusionGemmaの場合はその関門が16GBではなく18〜24GB級に上がります。第二に、収まった先では演算性能が体感を左右しうるため、VRAM容量だけでなく、行列演算の速さ(Tensor Coreの世代・規模)まで含めて比べておくと、後で伸びしろを見落としにくくなります。
速度と品質はトレードオフ|DiffusionGemmaは誰に向くか
DiffusionGemmaの速さは、品質とのトレードオフの上に成り立っています。Google公式のモデルカードが公表している、同じ26B-A4Bどうしの比較では、総合知識のMMLU Proが77.6%(DiffusionGemma)対82.6%(自己回帰版Gemma 4)、数学推論のAIME 2026(ツールなし)が69.1%対88.3%、コーディングのLiveCodeBench v6が69.1%対77.1%でした。いずれも自己回帰版が上で、特に多段の数学推論では約19ポイントと差が大きく開きます。これらはGoogleが公表した公式の比較値です。Google自身も、DiffusionGemmaの総合的な出力品質は標準Gemma 4より低いと説明しています。個別のベンチマークには拡散版が上回る項目もありますが、主要指標の傾向と公式の推奨は一致しています。
つまりDiffusionGemmaは、「速いが、推論やコーディングの確度は同規模の自己回帰版に譲る」モデルだと言えます。一方で、拡散方式は文章の途中を埋めたり、順不同で書き換えたりといった編集的な処理には構造的に向いています。Googleはこのモデルを実験的(experimental)と位置づけており、品質を最優先する用途では、自己回帰版のGemma 4が引き続き有力な選択肢になります。
向くケースと、向かないケース
速度と品質のバランスから整理すると、DiffusionGemmaが向くのは、単一ユーザーが低レイテンシで使う処理(対話でも長めの文章を生成する場面や、エージェント的に生成を何度も繰り返す処理)、コード補完や文章の途中編集といった順不同で埋めるタスク、そして新しい生成方式を自分の環境で観察したい場合です。低バッチ・単一アクセラレータでの低レイテンシは、公式に想定された強みです。
逆に利点が出にくいのは、多数のリクエストを高並列でさばくクラウドのサーバ用途です。高スループットのバッチ処理では自己回帰モデルの方が有利になり、拡散方式の旨味が薄れる、と公式も説明しています。また、回答の確度や推論の質を最優先する用途、VRAMが限られた環境(DiffusionGemma自体は18〜24GB級を要するため、16GB単体では不足)も不向きです。単純な短文チャットだけなら、自己回帰モデルでも体感は十分なことが多く、わざわざ移行する必要は薄いでしょう。
ローカルで動かすなら、VRAMの使いどころで考える
ローカル前提では、VRAMの割り当ても判断材料になります。DiffusionGemmaは量子化しても18〜24GB級のVRAMを要するため、16GBのGPU単体では収まりにくく、動かすなら24GBクラスか複数GPUでVRAMを束ねる構成になります。その容量を割くなら、同じ枠で動く自己回帰の高品質モデルと天秤にかける形です。16GB級のGPUでローカルLLMを回す前提なら、現時点では自己回帰版のGemma 4のような選択肢のほうが、確度・VRAMの収まり・ツールの成熟度の面で実務的でしょう。DiffusionGemmaは、順不同編集の強みが効く用途と、拡散方式という方向性の将来性を見据えて、環境が整えば試すモデル、という距離感が現実に即しています。重みが手元に来るオープンウェイトなので、こうした新方式を公称値だけでなく自分のハードウェアで確かめられる点は、ローカルで動かす価値の一つです。
まとめ|何を押さえ、次に何を確かめるか
DiffusionGemmaは、自己回帰の1トークンずつではなく、まとまり単位で文章を並列に整える拡散方式の実験的オープンモデルです。基盤はGemma 4の約25.2B MoEで、活性化するのは推論で約3.8B、Apache 2.0のオープンウェイトとしてRTXやDGX Sparkで動きます。
理解の順番としては、まず「自己回帰と拡散方式は何が違うのか」を押さえ、次に「速度は公称値であって手元の実測はこれから」という距離感を持ち、最後に「手元のGPUがVRAM容量(DiffusionGemmaなら18〜24GB級)と演算性能の両面で要件を満たすか」を確認する、という流れが堅実です。新しい方式だけに、確定した数字と公称値を分けて読むことが、そのまま判断の質につながります。
そして使うかどうかは、速度と品質のどちらを取るかで決まります。推論やコーディングの確度を優先するなら同規模の自己回帰版Gemma 4、低レイテンシや順不同編集が効く用途ならDiffusionGemma、という使い分けが現実的です。16GB級GPUでローカルに動かす前提なら、VRAMの収まりとツールの成熟度から今のところは自己回帰版を主軸に置き、DiffusionGemmaは環境が整い次第、新方式の伸びしろを見ながら試す、という距離感が無理のない選び方になります。
よくある質問
Q. DiffusionGemmaは普通のLLMと何が違いますか?
普通のLLMは自己回帰方式で1トークンずつ順番に生成します。DiffusionGemmaは拡散方式で、最大256トークンのまとまりを複数ステップで並列にデノイズして仕上げます。単一ユーザーの低レイテンシ処理に向いた設計で、公称では自己回帰の同等モデルより最大4〜5倍高速とされています。
Q. ローカルで動かすのにクラウド契約は要りますか?
要りません。Apache 2.0のオープンウェイトで配布され、NVIDIA RTXやDGX Spark上でローカル動作します。公開初日からHugging Face Transformers・vLLM・Unslothが対応しています。ただしWeb検索など外部接続を併用すればデータは外に出るため、外部送信を避けたい場合はローカルモデル単体で使う前提が必要です。
Q. VRAMは何GBあれば動きますか?
実装と精度で変わります。Googleの公式Transformers手順でフル精度(BF16)をそのまま読む場合は60GB超のGPUが前提です。量子化すれば下がり、Googleは18GB枠や24GBのRTX 5090/4090級に収まると説明しています。コミュニティ配布のQ4_K_M量子化版の動作目安が約24GB VRAMという数字もありますが、これはUnslothの配布モデルカード上の非公式な目安(2026-06-12時点)です。いずれにせよ16GB単体GPUでの全量GPU実行は要件未満で、現実的には24GBクラスの単体GPUか、複数GPUに分割できる構成が要ります(CPUオフロード等は未検証)。なお土台の自己回帰版gemma4:26bは当サイト実測でGPU総使用量15,612 MiB(約15.25 GiB)と16GBに収まりますが、これは拡散ヘッドを持たない自己回帰版の参考値です。
Q. 速度の「4〜5倍」は実測値ですか?
いいえ、公称値です。Googleの発表では最大4倍、DeepMindのモデルページでは4〜5倍、NVIDIAの発表ではおおむね最大4倍と、出典によって表現が異なります。単一H100で毎秒1,000トークン超、DGX Sparkで毎秒150トークン前後といった数字も公称です。当サイトではDiffusionGemma自体の速度は未計測で、土台の自己回帰版gemma4:26b(3回平均で約36.4 tokens/sec)のみ実測しています。
Q. DiffusionGemmaとベースのGemma 4、どちらを使えばいいですか?
品質や推論の確度を優先するなら、現状は自己回帰版のGemma 4が無難です。Google公式の比較でも、MMLU Pro・数学推論(AIME 2026)・コーディング(LiveCodeBench v6)のいずれもGemma 4が上回ります。DiffusionGemmaが効くのは、低レイテンシで反復生成する用途や、コード補完・途中編集のような順不同の処理です。速度と品質のどちらを取るか、用途で選ぶのが現実的です。
参考資料
- Google DeepMind: DiffusionGemma モデルページ
- Google AI for Developers: DiffusionGemma モデルカード(ベンチ・仕様の一次情報)
- Google 公式ブログ: DiffusionGemma — Faster Text Generation
- Google Developers Blog: DiffusionGemma the Developer Guide(VRAM目安・対応基盤)
- NVIDIA公式ブログ: NVIDIA Accelerates Google DeepMind’s DiffusionGemma for Local AI
- NVIDIA Developer Blog: Run DiffusionGemma on NVIDIA for Developer-Ready, High-Throughput Text Generation
- Unsloth: diffusiongemma-26B-A4B-it-GGUF(コミュニティ量子化版の配布元・VRAM目安の出典/非公式)
当サイトはAmazonアソシエイト・プログラムの参加者です。Amazonのアソシエイトとして、当サイトは適格販売により収入を得ています。

