
LTX 1 is a lightweight video generation AI model (2B parameters) released by Lightricks, positioned as a practical solution for commercial mass production on GPUs with VRAM 16GB class capacity. Source: Lightricks official LTX Video model page / Hugging Face Lightricks/LTX-Video model card
- RTX 5080: 5 minutes 9 seconds (309 s) per video, Peak VRAM 15.9 GB, Peak RAM +25.9 GB (author’s measurement / nvidia-smi measurement)
- RTX 5060 Ti (Oculink): 9 minutes 12 seconds (552 s) per video, Peak VRAM 16.0 GB, Peak RAM +27.2 GB (author’s measurement)
- The above times cover the LTX 1 model itself plus RIFE VFI interpolation. 4K upscaling is a separate process requiring additional time.
- LTX 2.3 (22B AV version) cannot be loaded with the standard loader, making commercial mass production on 16GB VRAM currently unrealistic.
- Author’s operational track record: Generated 928 videos in 3 months → Uploaded approximately 30% to Adobe Stock → Acceptance rate of 45.7% (based on Adobe Stock official review result emails from the last 4 days)
- Scope of This Verification
- Test Environment
- Measured File Sizes for Each LTX Version
- RTX 5080 vs RTX 5060 Ti Comparison (Same Workflow)
- Processes Not Included in the Measured Times of This Article (Important)
- VRAM / RAM / Time by Phase (RTX 5080 Details)
- Production Track Record: 928 Videos Generated in 3 Months, 45.7% Acceptance Rate on Adobe Stock
- Example of a Production-Grade Prompt for One Video (Real-World Deployment)
- 3 Reasons Why LTX 2.3 Is Not Suitable for Commercial Mass-Production on 16GB VRAM
- Three Options for 16GB VRAM Users
- Frequently Asked Questions
- Summary: Don’t chase the latest, mass-produce with proven, working models
- References
Scope of This Verification
This article is a primary record of real-world measurements of LTX 1 conducted by the author using an RTX 5080 (VRAM 16GB) and an RTX 5060 Ti 16GB (connected via Oculink) within the author’s production workflow. Measurements were taken using a configuration identical to the pre-production stage for generating assets for Adobe Stock: 1024×576 resolution, 241 frames, 50 steps, RIFE VFI (frame interpolation x2), and H264 mp4 output on ComfyUI. Source: ComfyUI Official (Comfy.Org) / RIFE Official GitHub (megvii-research/ECCV2022-RIFE)
To conclude upfront, LTX 1 is the realistic solution for commercial mass production of video generation with 16GB VRAM. While LTX 2.3 is the latest version, it cannot establish a stable mass-production line in a 16GB VRAM environment.
Test Environment
| Item | Configuration |
|---|---|
| Main GPU | NVIDIA RTX 5080 (VRAM 16GB GDDR7, PCIe 5.0) |
| Sub GPU | NVIDIA RTX 5060 Ti 16GB (via Oculink / MINISFORUM DEG1) |
| CPU | Intel Core i7-14700F |
| System RAM | DDR5 96GB |
| Storage | NVMe SSD 2TB x 2 |
| OS | Windows 11 |
| ComfyUI | v0.9.1 (embedded Python 3.12 / PyTorch 2.9.1+cu128) |
| Operational Model | ltx-video-2b-v0.9.1.safetensors (LTX 1) |
| Text Encoder | t5xxl_fp16.safetensors |
| Post-processing | RIFE VFI v4.9 (rife49.pth) frame interpolation x2 (30fps → 60fps) |
| Test Date | April 17, 2026 |
Source: Author’s actual test setup / Hugging Face Lightricks/LTX-Video / RIFE official release (v4.9)
Measured File Sizes for Each LTX Version
| Model | Size | Positioning |
|---|---|---|
| ltx-video-2b-v0.9.1 (LTX 1) | 5.72 GB | Lightweight and fast. Runs comfortably on 16GB VRAM. The author’s operational model. |
| ltxv-13b-0.9.7-distilled-fp8 | 15.69 GB | 13B distilled fp8. Barely fits on 16GB. |
| ltx-2-19b-dev-fp8 | 27.08 GB | 19B dev fp8. Offloading is required. |
| ltx-2.3-22b-distilled-fp8 (AV) | 29.53 GB | Latest version with audio support. Not compatible with the standard loader. |
Each size is a measured value obtained by directly running ls on the safetensors files in the author’s environment, and matches the sizes listed on the model cards on the Hugging Face Lightricks organization page. Source: Hugging Face Lightricks organization page (confirmed April 2026)
RTX 5080 vs RTX 5060 Ti Comparison (Same Workflow)
The same settings (1024×576, 241 frames, 50 steps, cfg 3.0, RIFE VFI x2) were run on both GPUs. In this article, the RTX 5080 is measured in bf16 mode, and the RTX 5060 Ti is measured in fp8 quantization mode, although both GPUs can operate in either bf16 or fp8.
Time, VRAM, and RAM Consumption per Generation
| Item | RTX 5080 (16GB) | RTX 5060 Ti 16GB (Oculink) | Difference |
|---|---|---|---|
| Total Generation Time | 309 seconds (5 min 9 sec) | 552 seconds (9 min 12 sec) | 5060 Ti is 1.79x slower |
| Peak VRAM | 15,890 MB | 16,004 MB | Almost identical (both maxed out) |
| Peak RAM Usage Increase | +25.9 GB | +27.2 GB | 5060 Ti is slightly higher |
| ComfyUI Settings at Measurement | –normalvram –bf16 | –normalvram –fp8_e4m3fn | Both can operate in bf16 / fp8 |
| Connection | PCIe 5.0 x16 (Internal) | Oculink (Equivalent to PCIe 4.0 x4) | Significant bandwidth difference |
Source: Author’s real machine nvidia-smi / Windows Performance Monitor measurements (2026-04-17)
Key Takeaways
- Generation time difference is about 1.8x. The RTX 5060 Ti + Oculink achieves approximately 56% of the speed of the internal RTX 5080.
- VRAM usage is nearly 16GB for both. It maxes out during the RIFE VFI frame interpolation stage.
- Works with both bf16 and fp8. You can choose based on the trade-off between precision and speed.
- Operable via Oculink. Although it takes longer, it completes the same quality and workflow as the internal card.
- During the initial model load, the Oculink bandwidth becomes a bottleneck, resulting in longer load times compared to the internal card.
- After inference begins, processing is primarily within VRAM, so the impact of the bandwidth difference is minimal.
- Power supply for the Oculink dock (750W dedicated PSU for DEG1) and GPU temperature management during long-term operation are critical.
Processes Not Included in the Measured Times of This Article (Important)
The above times of “5 minutes 9 seconds” and “9 minutes 12 seconds” represent the duration from LTX 1 video generation + RIFE VFI frame interpolation + H264 encoding. In the author’s production deployment, 4K upscaling processing follows this stage, which also requires a significant amount of time.
If you are creating final submission files for Adobe Stock (4K 60fps mp4), you need to plan your operations assuming that the 4K upscaling processing time will be added to the times cited in this article.
VRAM / RAM / Time by Phase (RTX 5080 Details)
| Phase | Elapsed Time | VRAM Usage | RAM Increase | Notes |
|---|---|---|---|---|
| Initial State | 0 s | 1,034 MB | 0 | Immediately after ComfyUI startup |
| Model Load | 0-5 s | 10,070 MB | +7.6 GB | Loading LTX 1 + T5-XXL + VAE |
| LTX 1 Generation | 5-155 s | 12,124 MB | +6.9 GB | Generating 50 steps · 241 frames |
| RIFE VFI Start | 155 s | 15,768 MB | +18.4 GB | Frame interpolation processing begins |
| RIFE VFI In Progress | 155-300 s | 15,890 MB (Peak) | +25.9 GB (Peak) | VRAM 16GB limit nearly reached |
| mp4 Encoding | 300-309 s | drop | Freed | Exporting H264 crf=0 |
Source: Author’s real machine nvidia-smi continuous sampling / Windows Task Manager RAM transition (2026-04-17)
It is RIFE VFI, not the LTX 1 model itself, that fills the 16GB
Measurements show that generation using only the LTX 1 model itself stays within 12 GB of VRAM. The 16GB limit is fully utilized during the RIFE VFI frame interpolation phase, where VRAM reaches 15.9 GB and system RAM increases by an additional 26 GB. The RIFE official GitHub README explicitly states that the required memory increases linearly in proportion to the number of interpolated frames.Source: megvii-research/ECCV2022-RIFE README (RIFE v4.9 series)
There are several strategies available for users with 16GB VRAM:
- A) Operate without frame interpolation (30fps output, VRAM stays within 12 GB)
- B) Use RIFE VFI while ensuring at least 64GB of RAM (the configuration in this article)
- C) Insert PurgeVRAM-style custom nodes for ComfyUI (community-developed nodes for forced GPU memory release) between nodes, enabling operation on a 12GB GPU
Even on a 32GB RAM environment, it is possible to generate works that pass review by minimizing OS and applications and using a lightweight configuration (24fps, 30fps, short duration), but for the 60fps high-resolution configuration in this article, 64GB or more of RAM is recommended. A 96GB configuration is the most stable with margin.
Production Track Record: 928 Videos Generated in 3 Months, 45.7% Acceptance Rate on Adobe Stock
This is actual data from operating LTX 1 on the same RTX 5080 environment from January to April 2026. The Adobe Stock figures are based on acceptance notification emails received from the company. Source: Adobe Stock Contributor Acceptance Notification Email (2026-04-13 to 2026-04-16 / Images with personal information redacted attached at the end of this article)
Actual Workflow (Generation → Upload → Acceptance)
The author’s operation is structured in three stages.
- Generate with LTX 1: A total of 928 videos over 3 months (January to April 2026, aggregated from the author’s local storage)
- Select candidates for upload via inspection: Approximately 30% of the generated videos (roughly around 280 videos) were uploaded to Adobe Stock
- Pass Adobe Stock review: An acceptance rate of 45.7% for the uploaded videos based on data from the most recent 4 days
The “percentage of total generated videos that are ultimately commercialized” is approximately 14% overall (30% × 45.7%). Adobe Stock has tightened its review of AI-generated assets since 2025, with an increasing number of rejections due to similar content already existing in their collection. Updates to review criteria for AI-generated content were also announced in the official Adobe Stock Contributor Help guidelines since 2025. Under these conditions, 45.7% falls within a practically usable range. Source: Adobe Stock Official Contributor Help (AI-Generated Content Guidelines)
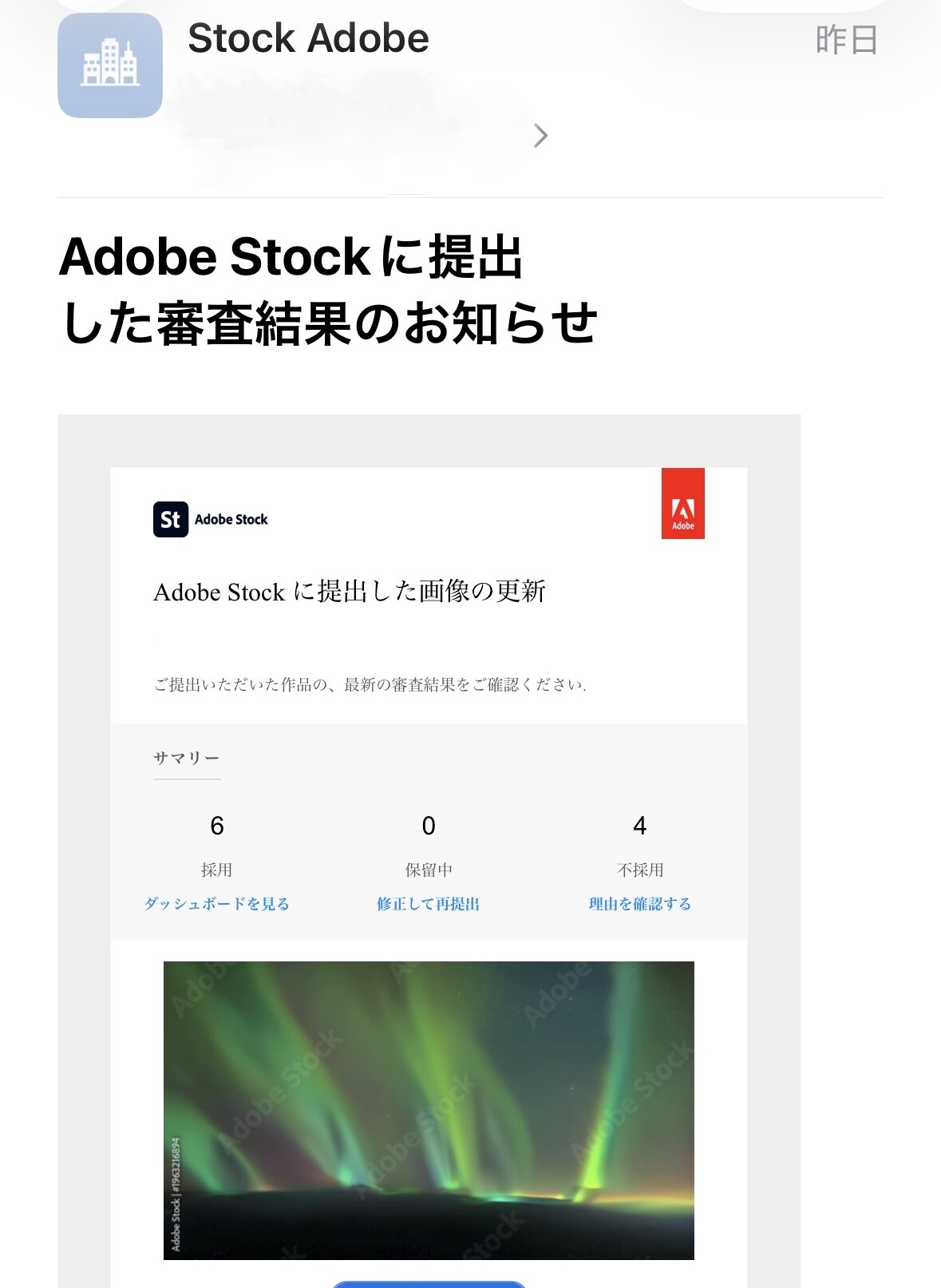
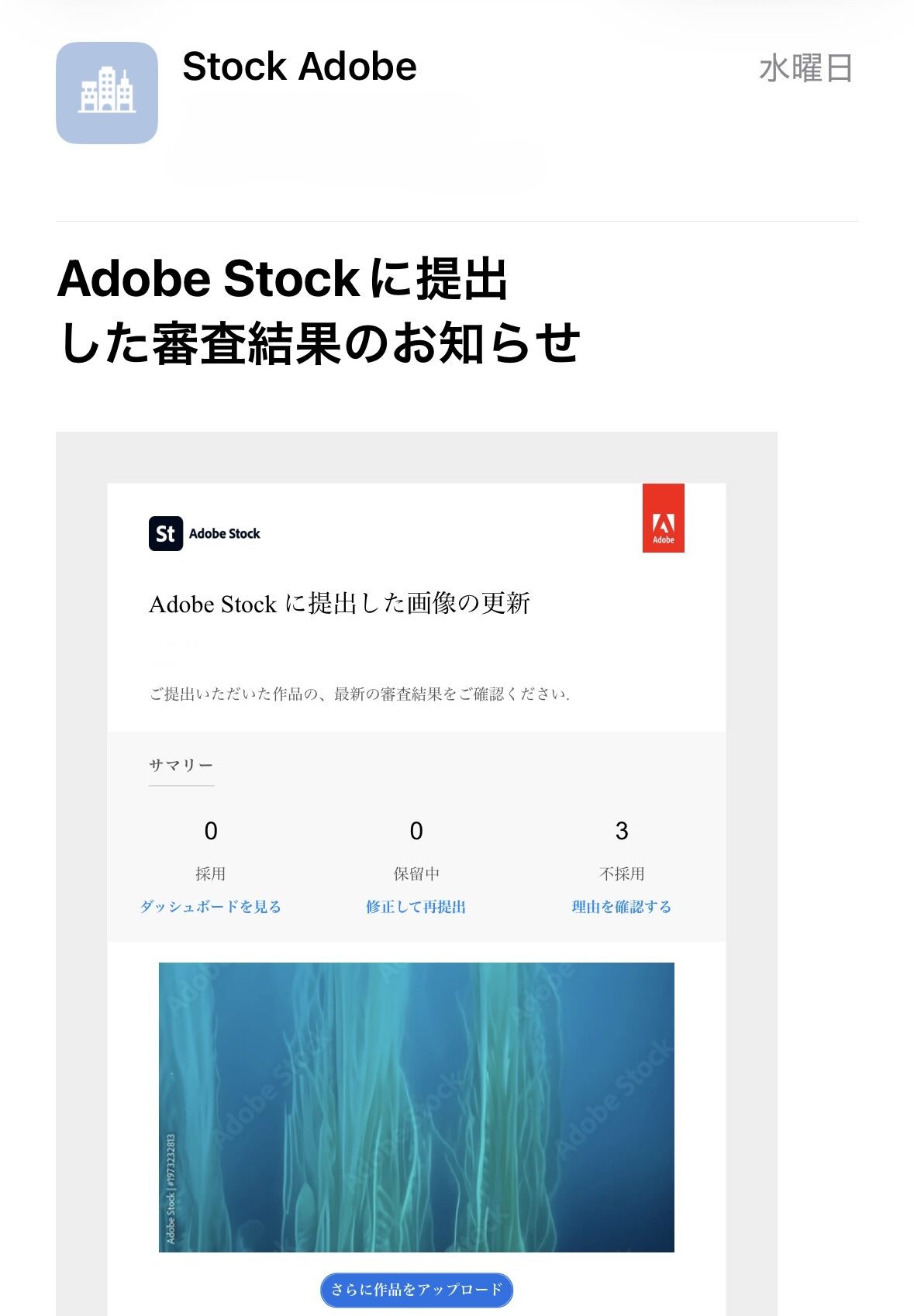
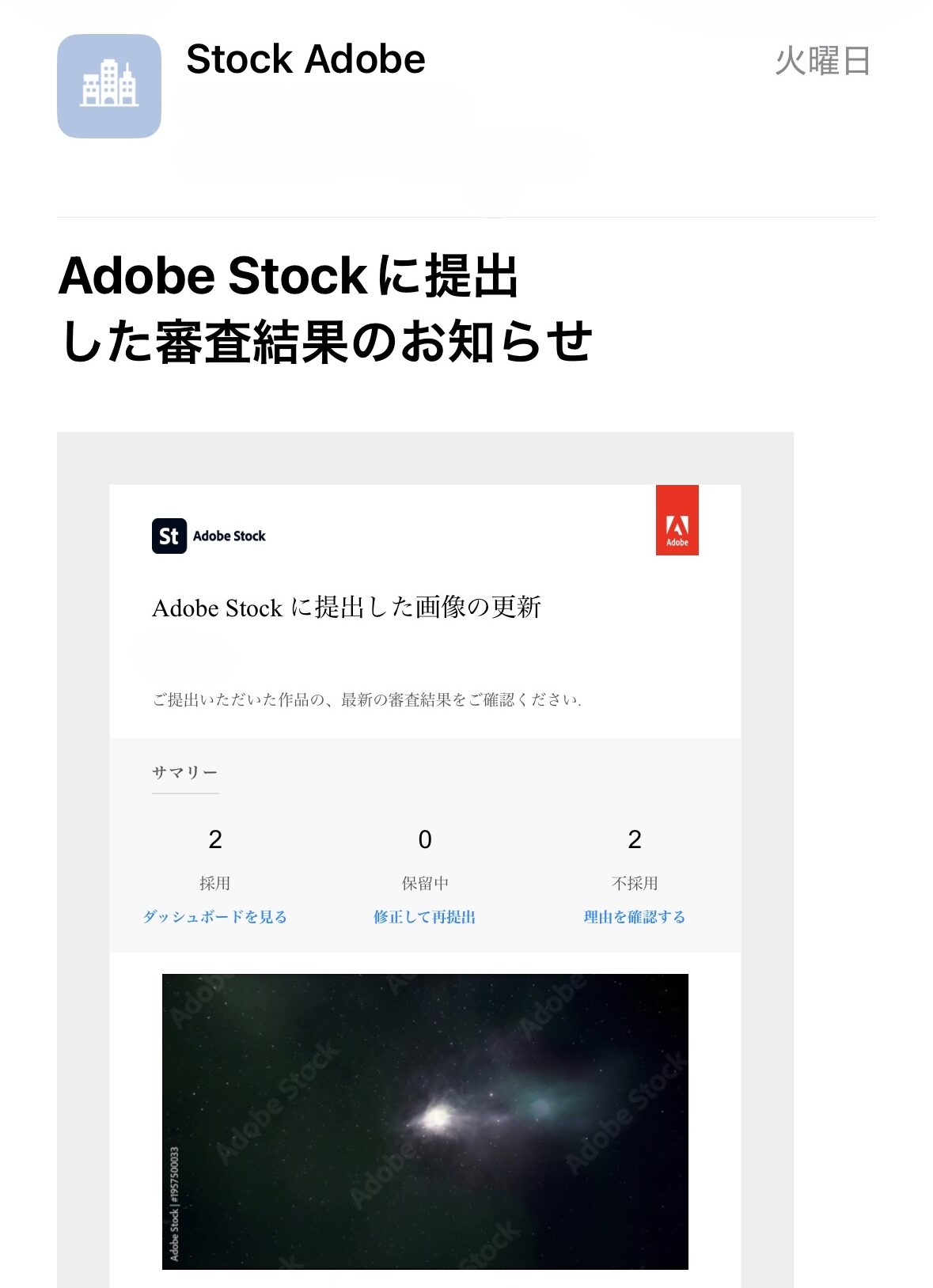
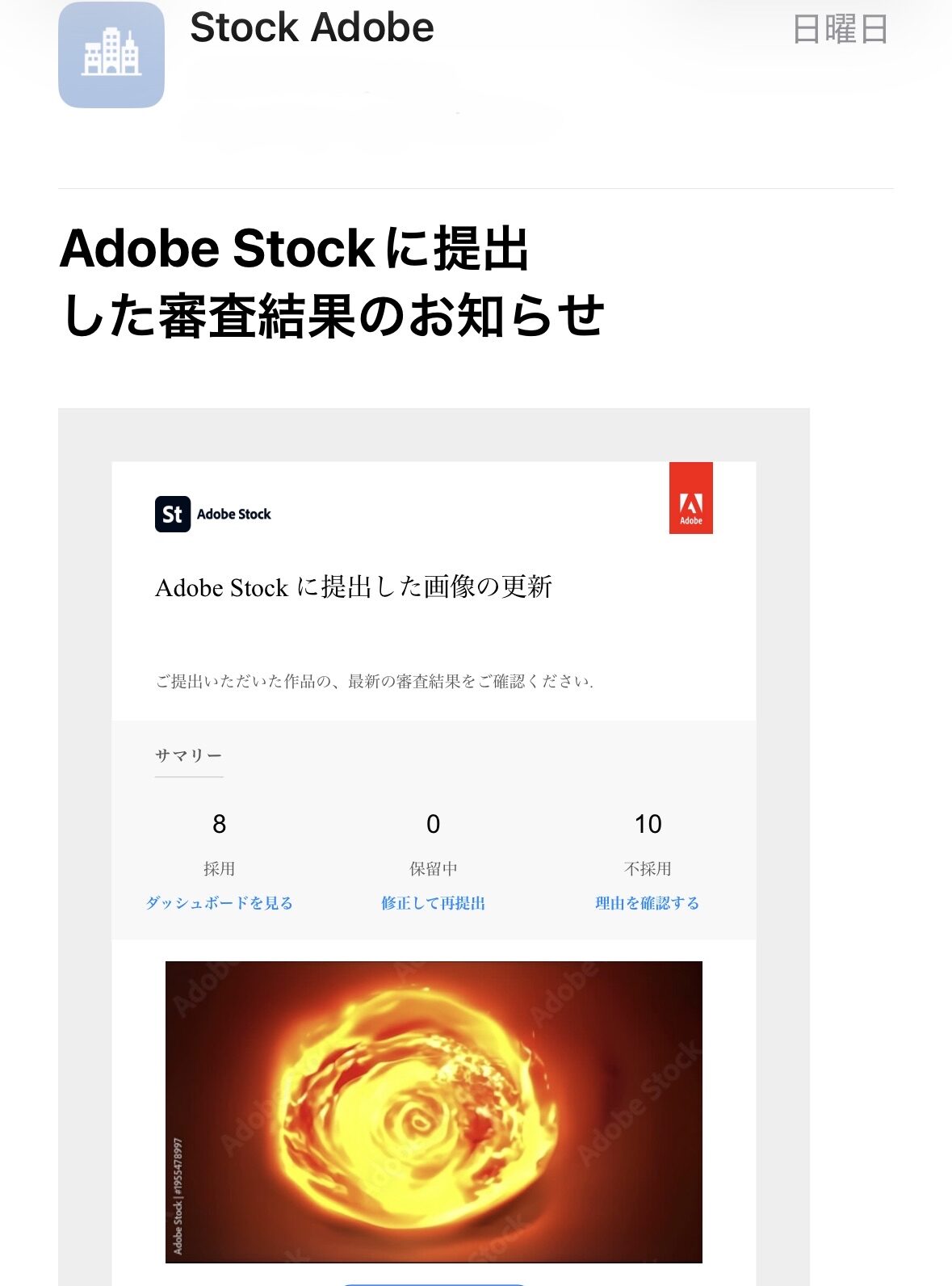
Adobe Stock Review Results (Most Recent 4 Days)
| Submission Date | Accepted | Rejected | Acceptance Rate |
|---|---|---|---|
| April 13, 2026 (Sun) | 8 videos | 10 videos | 44.4% |
| April 14, 2026 (Mon) | 2 videos | 2 videos | 50.0% |
| April 15, 2026 (Tue) | 0 videos | 3 videos | 0.0% |
| April 16, 2026 (Wed) | 6 videos | 4 videos | 60.0% |
| Total (4 Days) | 16 videos | 19 videos | 45.7% |
Source: Adobe Stock Official Review Result Emails (2026-04-13 to 2026-04-16, 4 supporting images attached at the end of this article)
Example of a Production-Grade Prompt for One Video (Real-World Deployment)
For reference, the author is publishing a production-grade prompt used to generate one video for Adobe Stock. This is far beyond the “simple 30-word prompts” generally introduced, densely weaving in English expressions of physical phenomena, cinematic terminology, optical parameters, and mood specifications to bring out the quality of LTX 1’s output.
The following is the actual prompt used for generating “Oil Slick Rainbow Macro (Iridescent Thin-Film Interference Macro Video).” Since it is unrealistic to write this level of detail manually every time, the author has built a prompt auto-generation system using a local LLM (Ollama + Gemma 3 12B GGUF). The specific generation logic is outside the scope of this article, but the prompt below is one of its outputs.
positive prompt
(Iridescent Thin-Film Interference: Oil Slick Rainbow Macro:1.3), (Low angle hero composition, subject rises from bottom edge, expansive upper negative space:1.2), Rainbow Band Drift Sequence, Marangoni convection spreading coefficient, Film drainage velocity gravity, Capillary number viscous-surface ratio, Thin-film equation lubrication, seamless looping motion, first and last frame match, stable camera, temporal coherence, smooth continuous motion, Tripod shot, locked off camera, stable composition, no movement, perfect framing, Central composition, Clear spatial structure, Rack focus shifting from foreground to background. The oil slicks surface flow exhibits Marangoni drift towards the right, with color bands migrating at approximately 1 mms, and interference pattern density increasing by 30 over 8 seconds At reflection angles between 40 to 50, hard directional spotlight, dramatic chiaroscuro, deep black shadows, high contrast, focused beam, Silver White Overexposed, Soft luminous pastel tones, dreamlike bloom and halation, iridescent prismatic nuances, ethereal atmospheric glow, angelic backlit translucency, subsurface scattering illumination, pearl-white highlights, celestial haze, Flat dark surface, Petroleum rainbow film, Oil slick thin-film optics, petroleum film thickness -, thin-film interference bands interference color, thermocapillary surface tension flow, iridescent band migration, angle-dependent structural color, Clear refractive index hydrocarbon film, ambient light iridescence, macro flat surface view, slow drift animation, Dreamlike beauty and weightless fantasy, angelic soft-focus atmosphere, luxury wellness and cosmetic aesthetic, serene relaxation mood. Cinematic 16:9, Widescreen, Anamorphic lens, Petroleum thin-film Marangoni band, Clear refractive index hydrocarbon surface, thin-film interference bands interference color, Angle-dependent structural color gradient, macro lens, 100mm, extreme close-up, shallow depth of field, bokeh, microscopic details,, super slow motion, weightless drift, graceful deceleration, ultra high resolution optics, optimal depth of field, maximum tonal depth, optical realism, diffraction-limited sharpness, zero distortion, sub-pixel detail, pristine optical quality, edge-to-edge sharpness, premium lens coatings, (no text:1.2)negative prompt
(text:2.0), (watermark:2.0), (logo:2.0), (ui:2.0), (hud:2.0), (digits:2.0), (numbers:2.0), (bad geometry:1.5), (amorphous:1.5), (unstructured:1.5), (muddy:1.5), (blurry focus:1.3), (static:1.5), (frozen:1.5), (statue:1.5), (still image:1.5), (solidified:1.3), (motionless:1.5), (grid:1.5), (mesh:1.5), (dots:1.5), (pixelated:1.5), (pattern:1.5), (human:1.5), (face:1.5), (hand:1.5), (skin:1.5), (animal:1.5), (low resolution:1.3), (artifacts:1.3), (morphing:1.5), (shaking:1.5), (flickering:1.5), (glitch:1.2), (sharp edges:1.5), (hard light:1.5), (industrial:1.5), (mechanical:1.5), (oversaturated:1.3), (heavy:1.3), (Pop:1.3), (Burst:1.3), (Dry:1.3), (Dull:1.3), (Matte:1.3), (Grey:1.3), (Black and White:1.3), (Solid:1.3), (Rock:1.3), (Wood:1.3), (Dirty:1.3), (Pollution:1.3), (Drug:1.3), (Trippy:1.3), (Oil pollution:1.3), (Chemical spill:1.3), (Toxic:1.3)LTX 1 can produce videos with simple prompts, but to maintain the acceptance rate for stock materials, such high-density descriptive specifications + extensive negative exclusion are effective. The prompt length exceeds 1500 characters for positive and over 500 characters for negative.
Concept of Mass-Generating Prompts via LLM (Initial Manual Template Example)
In mass-producing stock materials, writing similar prompts repeatedly leads to overlaps, resulting in “similar content” rejections during review. Initially, the author manually fed instructions into the Gemini Pro chat interface to batch-output video prompts with variations.
Below is a simplified version of the template used at that time. By pasting this directly into an LLM chat and requesting “Output N versions,” it would return N prompts ready for LTX 1.
# LTX 1 Video Prompt Batch Generation Template (Simplified)
[Common Conditions]
- Number of generations: N (e.g., 30)
- Purpose: positive + negative prompts for LTX 1 video generation
- Each must be unique, minimizing overlaps
[Example Generation Themes - Roughly Equal Distribution]
Theme A: Tactile Material Expression
Subject: High-viscosity liquid metal, surface tension, micro-bubbles, subsurface scattering
Reference Vocabulary: macro cinematography of viscous molten material, tactile density,
surface tension, subsurface scattering, anisotropic highlights
Theme B: Spectral Optical Phenomena
Subject: Light diffraction, refraction, dispersion, attenuation, bokeh
Reference Vocabulary: abstract spectral energy fluid, volumetric glowing particles,
fiber optic light trails, diffraction, anisotropic bokeh
Theme C: Micro-Biological Physics
Subject: Cell membranes, bioluminescence, organic tissue transparency
Reference Vocabulary: bioluminescent membrane, organic tissue transparency,
electron microscope aesthetics, subsurface scattering in organic matter
[Common Ending Tags (Added to end of positive each time)]
(black background:1.3), (best quality, 4K, uhd:1.2), ultra-detailed,
(seamless loop:1.3), (smooth motion:1.2)
[Common Negative (Must be included in negative)]
(no humans, no face, no hand, no bad anatomy:2.0)
(no text, no watermark, no logo:2.0)
(no architecture, no straight lines, no buildings:1.5)
(no distortion, no artifacts, no blurry, no halos:1.5)
[Output Rules]
- Output positive and negative sets for each video
- No explanations or greetings, only the prompt body
- Cycle through Theme A → B → C, dividing the specified number into 3 parts
Feeding this template to an LLM (Gemini Pro / Claude / ChatGPT / local LLM, etc.) yields 30 to 100 LTX 1 prompts in a single interaction. This is overwhelmingly faster than thinking of each one manually and is well-suited for mass production in terms of avoiding overlaps.
The author’s current workflow has evolved from this initial template to full automation via a local LLM (Ollama + Gemma 3 12B GGUF, resident on the 5060 Ti on the Oculink side). Specific mechanisms such as axis switching, quality tuning, and overlap detection are outside the scope of this article.
3 Reasons Why LTX 2.3 Is Not Suitable for Commercial Mass-Production on 16GB VRAM
1. Cannot Be Loaded with the Standard Loader (Technical Barrier)
The LTX 2.3 distilled version adopts the LTX AV (Audio-Video Integrated) architecture, with additional parameters for audio within the transformer. The GitHub README for ComfyUI-LTXVideo explicitly states that AV models can only be loaded via dedicated nodes. Loading fails due to dimension mismatch with ComfyUI’s standard CheckpointLoaderSimple. Source: Lightricks/ComfyUI-LTXVideo (official custom node repository)
RuntimeError: Error(s) in loading state_dict for LTXAVModel:
size mismatch for adaln_single.linear.bias:
copying a param with shape torch.Size([36864]) from checkpoint,
the shape in current model is torch.Size([24576]).To run it, you need to update the ComfyUI-LTXVideo custom node and reconstruct the workflow using AV-compatible nodes such as LTXVAudioVAELoader and LTXVSeparateAVLatent.
2. Model Size of 29.5GB Requires Offloading to Fit into 16GB VRAM
The fp8 checkpoint on disk is 29.53 GB. Fitting it into 16GB VRAM requires significant CPU offloading, which drastically reduces inference speed. While LTX 1 takes about 5 minutes per video (including RIFE VFI), LTX 2.3 with offloading could take tens of minutes. The Hugging Face model card for LTX-Video-2.3 also lists recommended VRAM as 24GB or higher. Source: Hugging Face Lightricks/LTX-Video-2.3 model card
3. Tuning Costs Do Not Justify Commercial ROI
Building an optimized workflow for LTX 2.3 (AV node wiring, VAE separation, tile optimization) requires several days to weeks. The author has already achieved a 45.7% acceptance rate on Adobe Stock with LTX 1, and the revenue impact of disrupting this to migrate to 2.3 is not justified.
Three Options for 16GB VRAM Users
Option A: Running LTX 1 Locally (Author’s Recommendation)
LTX 1 (ltx-video-2b-v0.9.1) is lightweight at 5.72 GB, with measured values of 5 minutes 9 seconds per clip on the RTX 5080 and 9 minutes 12 seconds per clip on the RTX 5060 Ti (Oculink) up to RIFE VFI. It has sufficient specifications for commercial mass production, with a track record of generating 928 clips over 3 months and an Adobe Stock acceptance rate of 45.7%.
Guidelines for GPU selection:
- RTX 5060 Ti 16GB: Approximately 105,000 JPY for new units (lowest price on price.com as of April 2026). The lowest-cost entry point for LTX 1 mass production. This is the measured model in this article.
- RTX 5070 / 5070 Ti: Shorter generation times than the 5060 Ti, offering a good balance between cost and speed in the mid-range.
- RTX 5080: Around 200,000 JPY (lowest price on price.com as of April 2026). The fastest line in this article.
Source: price.com Graphics Board Category (confirmed April 2026)
Option B: Cloud-based Video Generation Services
As of April 2026, cloud video generation is in a period of intense fluctuation. OpenAI Sora ended its web and app versions in April 2026, with API services also scheduled to cease in September. The following services are strong alternatives.
- Google Veo 3.1: Supports 4K 60fps and native 48kHz audio (Google DeepMind Official)
- Kling 3.0 (Kuaishou): High physical simulation accuracy, capable of generating long-form videos up to 2 minutes
- Runway Gen-4.5: Numerous adoption examples in film production (Runway Official), with strengths in camera movement control
- Seedance 2.0: Offers a free tier, allowing you to start at zero cost
No local GPU required, with monthly costs ranging from a few thousand to tens of thousands of yen. However, commercial license requirements and AI credit attribution requirements vary by service, so checking license conditions is essential when submitting to Adobe Stock, etc. Source: Each service’s official page (confirmed April 2026)
Option C: Investing in GPUs with 24GB or More VRAM
RTX 3090 (used from 150,000 JPY), RTX 4090 (300,000 JPY range), RTX 5090 (from 500,000 JPY), and professional RTX A5000 / A6000. This is a prerequisite for bringing out the true potential of LTX 2.3. Source: price.com Graphics Board Category (confirmed April 2026)
Frequently Asked Questions
Q. Can LTX 1 + RIFE VFI run on 12GB VRAM (RTX 4070 Super / RTX 3060 12GB, etc.)?
It is operable. However, you need to insert PurgeVRAM-style custom nodes (community-developed GPU memory force-release nodes, not standard) between each stage to release VRAM incrementally. Since the VRAM demand peaks differ between the LTX 1 generation phase and the RIFE VFI phase, purging VRAM in between allows it to fit within 12GB. The author has confirmed operation with the same workflow on an RTX 4070 Super (12GB) environment, with generation time increasing only slightly compared to the 5080 / 5060 Ti, remaining within practical limits.
Q. Can it run on 32GB RAM?
It is tight for the full configuration (1024×576, 241 frames, RIFE VFI, 60fps) due to a peak RAM usage of +26 GB. However, it can operate on a 32GB RAM environment with lightweight settings (24fps, 30fps, reduced frame count, lower resolution), and the author has experience producing works that passed Adobe Stock review. For mass production, 64GB or more of RAM is recommended, with 96GB being the preferred specification.
Q. Can it be used without RIFE VFI?
Yes. Removing RIFE VFI reduces the requirement to only the LTX 1 generation phase, needing 12 GB of VRAM and 150 seconds of generation time (on an RTX 5080). The output will be 30fps, but since Adobe Stock accepts 30fps content, it can be omitted depending on quality requirements.
Q. Which should I choose: the RTX 5060 Ti 16GB or the 5070 / 5070 Ti?
It depends on whether you prioritize budget or speed. The 5060 Ti 16GB offers the lowest cost at around 105,000 yen, with a measured time of 9 minutes 12 seconds per video (via Oculink) in this article. The 5070 / 5070 Ti has shorter generation times than the 5060 Ti, making it easier to increase the number of videos produced per day. For commercial operations focusing on yield, the 5070 class is practical; for small-scale operations or those wishing to minimize initial investment, the 5060 Ti 16GB is sufficient.
Q. How do I handle the state_dict mismatch error for LTX 2.3?
Because the LTX 2.3 distilled version uses the AV architecture, it cannot be loaded with the standard CheckpointLoaderSimple. Update the ComfyUI-LTXVideo custom node and load the official workflow JSON from example_workflows/2.3. Dedicated nodes such as LTXVAudioVAELoader are required. Source: Lightricks/ComfyUI-LTXVideo example_workflows/2.3 directory
Q. What is the actual commercialization yield?
Approximately 14% of total generations (30% inspection selection × 45.7% acceptance rate). Adobe Stock has tightened its review of AI-generated assets since 2025, and cases of rejection due to similar content detection (similar content already in our collection) are increasing. In this context, an acceptance rate of 45.7% can be considered within a practically usable range.
Summary: Don’t chase the latest, mass-produce with proven, working models
As of April 2026, if you aim for commercial video mass production on a GPU with 16GB VRAM, LTX 1 (the lightweight 2B version) is the realistic solution, rather than the latest LTX 2.3.
Measured values: 5 minutes 9 seconds per video on RTX 5080, 9 minutes 12 seconds per video on RTX 5060 Ti (Oculink) (LTX 1 + RIFE VFI). The 4K upscaling process requires additional time as a separate step, but it is possible to mass-produce for commercial use within the tight limits of 16GB VRAM. Ensuring 64GB or more of RAM (96GB recommended) allows for stable operation; there are experiences of passing review with 32GB RAM under lightweight settings, and 12GB VRAM is also operable when combined with PurgeVRAM-style custom nodes.
If you want to try LTX 2.3, you have the option to switch to a GPU with 24GB or more VRAM, or use it via cloud services such as Lightricks’ official LTX Studio, Fal.ai, or Replicate. Since these are pay-as-you-go, it is practical to test the behavior on the cloud before deciding on local migration. On the other hand, if you are starting video mass production now with 16GB VRAM, a safe choice is to start with a configuration of LTX 1 + RTX 5060 Ti 16GB (from 105,000 yen) or RTX 5080 + 64GB or more RAM.
The information in this article is as of the date of publication. Evaluations may change due to product updates, third-party benchmarks, price fluctuations, or changes in supported runtimes. It is recommended to re-verify content after a certain period has passed.
References
- Hugging Face Official: Lightricks/LTX-Video Model Card
- GitHub Official: Lightricks/ComfyUI-LTXVideo (Official ComfyUI Node for LTX Video)
- GitHub Official: megvii-research/ECCV2022-RIFE (RIFE Frame Interpolation)
- NVIDIA Official: GeForce RTX 5080 Product Page
- Adobe Official: Adobe Stock Contributor Generative AI Content Guidelines
